تعريف الفرضية
الفرضية (بالإنجليزية: Hypothesis)، مفرد فرضيات، كأحد مفاهيم البحث العلمي، هي تفسير مُقترح ومؤقت لظاهرة ما في المجتمع، ويشترط المنهج العلمي أن يكون بالإمكان اختبار الفرضية والتأكد من صحتها فبل أن تُصبح حقيقية علمية أو معرفة مؤكدة.
والأصل في منهجية البحث العلمي أن يقوم العلماء ببناء الفرضيات العلمية على المُلاحظات السابقة التي لا يمكن تفسيرها بشكل واضح بالنظريات أو الحقائق العلمية المتوفرة، ثم اختبار هذه الفرضيات والتأكد من صحتها أو عدم صحتها بطرق علمية.
المحتويات
الفرضية والنظرية أو الحقيقة العلمية
تختلف الفرضية العلمية عن النظرية أو الحقيقة العلمية، كما أن الفرضية لا تُكافئ النظرية أو الحقيقة العلمية حتى وإن استُخدمت كلمات فرضية أو نظرية بشكل مترادف في سياق موضوع البحث في أغلب الأحيان.
والفرضية الإجرائية هي فرضية مقبولة ومُقترحة بشكل مؤقت من أجل المزيد من البحث والتحليل والاختبار ضمن عملية متكاملة تبدأ بالتخمين أو طرح فكرة علمية وتنتهي إما بتأكيدها أو بنفيها، أو بالدعوة إلى إجراء المزيد من البحوث والاختبارات حول مسألة البحث.
الفرضية في علم المنطق
كما يوجد معنى مختلف لمصطلح الفرضية في علم المنطق، بحيث يمكن أن يُشير إلى المقدمات المُساقة في قضية ما والتي إن صحّت فإنها تؤدي إلى النتائج.
مثلا، في القضية المنطقية التالية:
إذا كان (س) فإن (ص)
حيث:
س = المقدم، ص = التالي
يُطلق على (س)، وهي هنا المقدمة في القضية المنطقية، اسم الفرضية أو الافتراض الذي لو تحقق فإنه يؤدي إلى النتائج أو (التالي) المتمثلة هنا في (ص).
بمعنى آخر، فإن (س) تُمثل الافتراض في سؤال من نوع: ماذا لو كان كذا صحيحًا؟
استخدامات الفرضية
تُستخدم الفرضية بشكل واسع في البحث العلمي وذلك من خلال طرحها في البحث الذي يُخطط الباحث إجراؤه باعتبارها أفكارًا أو تصورات مؤقتة تستلزم الاختبار والتقييم ومن ثم التأكيد أو النفي خلال تنفيذ البحث.
ومن أجل اختبار الفرضية بطريقة علمية يحتاج الباحث الذي يضع الفرضية إلى اتباع أسلوب البحث العلمي في اختبار الفرضيات الإحصائية وتفنيدها بهدف تأكيدها أو نفيها. وقد تُصبح الفرضية التي يتم تأكيدها حقيقة علمية أو نظرية مؤكدة.
كما تُستخدم الفرضية في علم ريادة الأعمال بهدف التطوير والتجديد وذلك من خلال صياغة أفكار مؤقتة داخل بيئة العمل ويتم تقييم الفرضية واختبارها ومن ثم التأكد من صحتها أو نفيها باستخدام الاختبارات الموجهة التكذيبية أو التحققية، واستثمارها بالشكل المناسب لصالح تطوير الأعمال والتخطيط ورفع كفاءة الأداء والإنتاجية.
شكل الفرضية
عادة ما تأتي الفرضية العلمية في صورة نموذج رياضي أو معادلة رياضية، كما يمكن صياغة الفرضيات لغويًا والتعبير عنها بالعبارات اللغوية بدون التطرق للمعادلات الرياضية، كالإشارة إلى أسباب ظاهرة ما بشكل عام، أو تفسيرها بشكل علمي.
الأمثلة التالية توضح نموذج لكل شكل من أشكال الفرضيات:
فرضية على شكل نموذج رياضي: (مجموع متتالية هندسية حدها الأول 1/2 وأساسها 1/2)
1/2 + 1/4 + 1/8 + 1/16 + ……… إلى ما لا نهاية = 1
فرضية على شكل عبارة مُصاغة لغويًا:
“تدني نتائج امتحانات الطلاب التي تتزامن مع نهائيات كأس العالم”.
اختبار الفرضيات الإحصائية
تؤدي الفرضية المفيدة في البحث العلمي إلى تنبؤات من خلال التفكير المنطقي، كأن تتنبأ الفرضية بنتائج تجربة معملية أو بالمُلاحظة لظاهرة معينة في الطبيعة أو المجتمع. وقد تتنبأ الفرضية أيضًا بطريقة الإحصائيات التي يتم حصرها وتتعلق بظاهرة معينة في الطبيعة أو المجتمع، كما يمكن أن تتنبأ الفرضية من خلال نظرية الاحتمالات وتطبيقاتها في مختلف المجالات.
ويؤكد فلاسفة العلم بأن الفرضية في البحث العلمي يجب أن تكون قابلة للتكذيب، وأنه لا يمكن النظر إلى القضية أو النظرية باعتبارها علمية إذا لم يتوفر احتمالية لكذبها. ورفض فلاسفة العلم الآخرون معيار قابلية التكذيب أو استكملوه بمعايير أخرى مثل التحققية أو الترابطية. ويتضمن المنهج العلمي التجريب، من أجل اختبار قابلية بعض الفرضيات للإجابة بشكل كافِ على السؤال قيد البحث. وفي المقابل، ليس من المرجّح أن تُقدم الملاحظة غير الموجهة نتائج غير مُفسَّرة أو أسئلة مفتوحة في العلوم، مثل إعداد تجربة حاسمة وحيدة من أجل اختبار الفرضية. كما أنه يمكن أن تُستخدم التجربة الفكرية من أجل اختبار الفرضية.
وتتطلب معظم أنواع البحث العلمي والعديد من البحوث بشكل عام عمليات اختبار الفرضيات الإحصائية، وأبسط الفرضيات هي تلك الفرضية المتعلقة بعينة واحدة، أي اختيار مجموعة واحدة من الأفراد كمجموعة جزئية من المجموعة الكلية أو المشار إليها عادة بمجتمع الدراسة، ثم جمع البيانات المتعلقة بالمتغير أو المتغيرات محل البحث باستخدام الأداة التي يحددها الباحث بحيث يتوفر لديه معلومة واحدة، (علامة على اختبار تحصيلي مثلا) تدل على مقدار المتغير عند الفرد الواحد.
أما إذا توفر معلومتين للفرد الواحد (بمعنى مجموعتين غير مستقلتين من البيانات، مثل مجموعة العلامات على اختبار تحصيلي في الرياضيات ومجموعة أخرى من العلامات على اختبار تحصيلي في العلوم)، أو تم اختيار مجموعتين من الأفراد وبالتالي مجموعتين من البيانات المستقلة (إناث وذكور مثلا)، فإن غرض الباحث هنا اختبار فرضية متعلقة بمجموعتين بغرض التعرف على كونهما من مجتمع واحد أم من مجتمعين مختلفين بالنسبة للمتغير.
التوزيعات الاحتمالية ودرجة الحرية
باعتبارها أحد المراحل المهمة من مراحل خطة البحث العلمي التي تأتي بعد مرحلة جمع البيانات والتحليل الإحصائي للبيانات، وحتى نتمكن من فهم اختبار الفرضيات الإحصائية ينبغي أولا شرح المقصود بالتوزيعات الاحتمالية وأنواعها وما يُطلق عليه درجة الحرية في البحث العلمي.
مفهوم التوزيعات الاحتمالية
التوزيعات الاحتمالية أو التوزيعات النظرية، هي توزيعات تخضع لمعادلات رياضية مبنية على فكرة الاحتمال، حيث يمكن الربط بين أي علامة في التوزيع والمساحة تحت المنحنى الدالة على الاحتمال أو الدالة على نسبة التكرارات التي تقع بين تلك العلامة وأي علامة أخرى ضمن المدى النظري للتوزيع.
تأتي أهمية الحديث عن التوزيعات النظرية من دورها في الإحصاء الاستدلالي، بمعنى الاستدلال على معالم المجتمع (بالإنجليزية: Parameters) من إحصائيات العينة أو (بالإنجليزية: Statistics)، ولا بد من أن يرافق هذا الاستدلال نسبة من الخطأ، وأبرز مصدر للخطأ هو الخطأ العيني (بالإنجليزية: Sampling Error).
وسوف يتم شرح هذه المصطلحات بالتفصيل.
1. التوزيع الاعتدالي القياسي Z
التوزيع الذي يتعامل معه الباحث عادة هو توزيع عينة أو (بالإنجليزية: Sample Distribution)، متوسطه (س) وانحراف معياري (ع). إلا أن الهدف هو تقدير معالم المجتمع من إحصائيات العينة. فربما كان هذا التقدير متحيزًا بدرجة قد تكون عالية بالنسبة لبعض المعالم. وإذا تم اختيار عدة عينات من نفس المجتمع نحصل على عدة توزيعات اعتدالية تختلف فقط في المتوسط الحسابي والانحراف المعياري، ومن هنا جاءت فكرة التوزيع الاعتدالي القياسي أو (بالإنجليزية: Standard Normal Distribution) وهو منحنى يمثل جميع التوزيعات الاعتدالية بمتوسط = صفر وانحراف معياري = 1.00.
ولذلك جاءت فكرة تحويل العلامات الخام إلى علامات معيارية زائية (Z) أو (ز)، حيث:
Z = (س – μ) ÷ σ
حيث:
- س = المتوسط الحسابي للعينة
- μ = المتوسط الحسابي للمجتمع
- ع = الانحراف المعياري للعينة
- σ = الانحراف المعياري للمجتمع
2. توزيع ستيودنت t
قد لا تكون معالم المجتمع الإحصائي ( μ و σ ) معروفة لدى الباحث ولذلك فهو يقدرها من إحصائيات العينة. ولأن دقة التقدير تعتمد على درجة تحيز العينة حيث يتوقع أن يزداد هذا التحيز بنقصان حجم العينة، وكذلك زيادة التباين لتوزيع (t)، وبالعكس فإن زيادة حجم العينة يؤدي إلى نقصان التباين نتيجة لنقصان الخطأ العيني، ولذلك يعتبر توزيع ستيودنت t (بالإنجليزية: Student’s t) من بين عدة توزيعات مثل توزيع فيشر F وتوزيع كاي تربيع (كا2) التي راعت الزيادة في الخطأ الناتج عن نقصان حجم العينة من خلال فكرة درجة الحرية.
درجة الحرية
يقصد بدرجة الحرية (بالإنجليزية: Degree of Freedom) عدد المشاهدات المستقلة المستخدمة في تقدير إحدى معالم المجتمع الإحصائي، وهي في حالة الخطأ المعياري = ن – 1. بمعنى أنه يوجد محدِدًا واحدًا لعدد الانحرافات المتضمنة في حساب الانحراف المعياري وهو أن مجموع الانحرافات = صفر لأن نقطة الإسناد في حساب الانحراف المعياري هي المتوسط الحسابي.
ولحساب قيمة العلامة التائية:
t = ( س – ميو(μ)) ÷ ( ع / الجذر التربيعي لعدد أفراد العينة )
حيث: س المتوسط الحسابي للعينة، μ المتوسط الحسابي للمجتمع، ع الانحراف المعياري للعينة.
3. توزيع كاي تربيع كا2
يعتبر توزيع Z المشار إليه سابقًا حالة خاصة في توزيع أعم هو توزيع كاي تربيع (بالإنجليزية: Chi-Square) والذي يُرمز إليه بالرمز كا2، ويعرف كاي تربيع إحصائيًا بأنه مجموع مربعات العلامات المعيارية.
أي أن:
كا2 = مجموع ( Z2 )
وبما أن عدد الانحرافات المعيارية يعتمد على عدد العناصر المأخوذة من المجتمع في كل مرة، فإن توزيع كا2 يشبه توزيع t من حيث اعتماده على درجة الحرية.
فإذا كانت درجة الحرية = 1
فإن توزيع Z2 هو نفسه توزيع كا2.
أي أن Z = الجذر التربيعي ل كا2.
وبذلك يمكن استنتاج ما يلي:
- أن توزيع Z حالة خاصة من توزيع كا2.
- لا يوجد قيم سالبة في توزيع كا2 وبالتالي فإن قيمه تمتد من صفر إلى مالانهاية.
- أن العلاقة بين كا2، Z علاقة انحنائية وليست خطية.
إذا زاد عدد العناصر عن واحد (اثنان مثلا) فإن توزيع Z12 + Z22 هو توزيع كا2 بدرجات حرية 2.
لا تشترط توزيعات t أن تكون البيانات على المتغير التابع واقعة على مقياس فئوي، كما لا تشترط تحقق الافتراضات التي تتطلبها الإحصائيات أو الاختبارات البارامترية مثل اختبار Z و t و F الذي سيرد لاحقًا. ولذلك تتعدد استعمالات اختبار كا2 ومن أهمها:
استعمالات توزيع كا2
1. اختبار فرضية الدلالة الإحصائية للتباين لعينة واحدة والتي يمكن أن تأخذ الصورة التالية في صياغة الفرضية:
ف. : 2σ + أ
مقابل فرضية بديلة موجهة أو غير موجهة حسب تحديد الباحث باستخدام المعادلة:
كا2 = (ن-1) ع2 / أ
2. اختبار درجة التوافق أو الملائمة مثل توافق التكرار الملاحظ (ت) مع التكرار المتوقع (تم) لعينة واحدة وبالطبع فإن تقدير التكرار المتوقع لا بد وأن يرتكز على خلفية نظرية.
3. اختبار دلالة الفرق بين مجموعتين أو أكثر على متغير أسمي بفئتين (مستويين) أو أكثر. حيث يقوم الباحث هنا بعمل لوحة اقتران ذات بعدين يشكل أحدهما المجموعات والثاني يشكل مستويات المتغير الإسمي. وبالطبع فإن أبسط هذه اللوحات هي لوحة الاقتران الثنائية كما لاحظنا في حساب معامل ارتباط فاي.
يمكن أن تكون إحدى طرق الاختبار للفرضية هنا هي اختبار الاستقلالية الذي يُستخدم في الإحصائي كا2.
4. توزيع فيشر F
الحديث عن توزيع فيشر F أو (بالإنجليزية: Fisher Distribution)، هو استمرارية للحديث عن توزيع كا2، ويوضح التعريف الإحصائي العلاقة بينهما، حيث يعرف الإحصائي F بأنه نسبة إحصائي كا2 مقسومًا على درجات الحرية الخاصة به إلى إحصائي كا2 آخر مقسومًا على درجات الحرية الخاصة به.
وباستخدام المعادلة:
كا2 = (ن-1) ع2 / أ
فإن الإحصائي F هو تباين عينة ع12 إلى تباين عينة أخرى ع22. ولذلك فإن من أهم استخدامات الإحصائي F في الإحصاء الاستدلالي هو اختبار تجانس التباين لعينتين أو أكثر.
ملاحظة
لم تعد التحليلات الإحصائية مشكلة مهما كانت درجة تعقيدها بسبب توفر برامج الحاسوب، ولذلك فإن دور الباحث هو اختيار الإحصائي المناسب وتطبيقه في الحاسوب ومن ثم التأمل في النواتج، وانتقاء ما هو ضروري لتضمينه في تقرير البحث.
يمكن الاطلاع على المراجع التعليمية المتخصصة في شرح وتبسيط استخدام برنامج التحليل الإحصائي SPSS ضمن المراجع التعليمية في مركز المساعدة على موقع مركز البحوث والدراسات متعدد التخصصات.
مركز المساعدة أو المراجع التعليمية – مركز البحوث والدراسات متعدد التخصصات – MDRS CENTER
صياغة الفرضية الإحصائية
تعرف الفرضية بأنها حدس أو تخمين حول إحصائي مجتمع أو أكثر. فقد يفترض الباحث أن متوسط نسبة ذكاء مجتمع الطلبة في مؤسسة تعليمية معينة تختلف عن الطبيعي، فإذا كان متوسط نسبة الذكاء = 100 ومتوسط نسبة ذكاء الطلبة في المؤسسة = μ فإن فرضية البحث أو الدراسة تقول بأن μ ≠ 100، وكأن الباحث يقول ضمنًا بأن مجتمع طلبة المؤسسة مجتمع غير طبيعي من حيث نسبة الذكاء، ولو كان طبيعيًا لكان μ = 100.
هذا مجرد مثال يشير إلى أن أي بحث ينطوي بصورة ضمنية أو صريحة على نوعين من الفرضيات وهما:
- الفرضية الصفرية
- أو الفرضية البديلة
الفرضية الصفرية
والفرضية الصفرية (ف.)، (بالإنجليزية: Null Hypothesis)، هي التي تشير إلى أن الاختلاف في قيمة إحصائي العينة المأخوذ من مجتمع التجريب عن قيمته في المجتمع الأصل هو اختلاف يرجع إلى الصدفة. أو أن الفرق بين إحصائي عينة ونفس الإحصائي في عينة أخرى هو فرق صدفة، أي فرقًا ليس له قيمة وأنهما بالفعل لا ينسبان إلى مجتمعين مختلفين.
الأمثلة التالية توضح صياغة الفرضيات الصفرية:
ف. : موقف الطلبة (قبول أو رفض) بالنسبة لقرار معين لا يعتمد على الجنس (ذكر أو أنثى).
ف. : μ = μ1 (مقارنة إحصائي العينة بإحصائي مجتمع قيمته معروفة).
الفرضية البديلة
الفرضية البديلة (ف1)، أو (بالإنجليزية: Alternative Hypothesis)، هي الفرضية التي يحاول الباحث إثباتها مقابل رفضه للفرضية الصفرية. وتسمى الفرضية البديلة بفرضية البحث حيث يفترض الباحث أن تدعم نتائج البحث ما كان قد توقعه من خلال الإطار النظري الذي كونه عن المشكلة مدار البحث، والذي يشير عادة إلى وجود الفرق أو إلى عدم التساوي المشار إليه في الفرضية الصفرية.
ولذلك تُصاغ الفرضية البديلة بطريقتين هما:
1. الفرضية غير المتجهة
الفرضية الغير متجهة أو (بالإنجليزية: Non Directional) تُشير إلى عدم التساوي دون تحديد للاتجاه. فقد لا توجد مؤشرات تدل على أن طريقة تدريس معينة ذات أثر أقوى أو أضعف من تأثير طريقة أخرى على تحصيل الطلبة في مبحث معين. ولكن كل ما يعتقده الباحث هو أنهما يختلفان في تأثيرهما دون أن يتحيز لطريقة معينة. ولذلك تظهر الصياغة الرمزية لبعض هذه الفرضيات بالطريقة التالية:
ف1 : μ ≠ μ0 لمجموعة واحدة
أو:
ف1 : μ2 ≠ μ1 لمجموعتين
أو:
ف1 : μ3 ≠ μ2 ≠ μ1 لثلاث مجموعات
2. الفرضية المتجهة
الفرضية المتجهة أو (بالإنجليزية: Directional) تشير إلى عدم التساوي مع تحديد للاتجاه. حيث يتوقع الباحث من خلال الإطار النظري للمشكلة بأن متوسط نسبة ذكاء مجتمع معين أعلى أو أقل من الطبيعي، أو أن أثر طريقة تدريس معينة على التحصيل في مبحث معين أقوى أو أضعف من تأثير طريقة أخرى.
ولذلك تظهر الصياغة الرمزية لمثل هذه الفرضيات بالصورة التالية:
ف1 : μ < μ0 أو ف1 : μ > μ0
أو:
ف1 : μ2 < μ1 أو ف1 : μ2 > μ1
نظرًا لأن صياغة الفرضية هو من العناصر الأساسية لخطة البحث العلمي الأولية التي يبدأ بها الباحث قبل بدء إجراءات البحث فإنه يُنصح بقراءة المزيد حول صياغة الفرضيات كأحد عناصر خطة البحث العلمي من خلال قراءة الموضوع التالي:
موسوعة البحث العلمي – مركز البحوث والدراسات متعدد التخصصات
الأخطاء في اختبار الفرضيات
يتخذ الباحث عادة قرارات تتعلق بتقدير إحصائي في مجتمع من إحصائي عينة أو تتعلق بفرضية إحصائية معينة من حيث قبولها أو رفضها. وبما أن هذه القرارات تعتمد على عينة بيانات إحصائية وليس على جميع البيانات ذات العلاقة بالإحصائي المطلوب. فإن القرار لا بد وأن ينطوي على نسبة من الخطأ، حيث يعتمد مقدار الخطأ على درجة التطرف في اختيار العينة. وبالطبع فإنه يتوقع أن يكون احتمال اختيار عينة متطرفة صغيرًا إذا تم اختيارها بالطريقة المناسبة أو أن حجم العينة كبير نسبيًا.
وبما أن قرار الباحث يتلخص إما برفض الفرضية الصفرية أو أنه لا يستطيع رفضها من خلال البيانات المتوفرة (أو بمعنى آخر قبولها) فإنه يتوقع أن يقع بنوعين من الأخطاء في اتخاذه للقرارات حول الفرضية الصفرية.
أنواع الخطأ في اختبار الفرضية
يبين الجدول التالي نوعين من الأخطاء التي قد يرتكبها الباحث عند اتخاذه لأربعة أنواع من القرارات خلال مرحلة اختبار الفرضية:
| حقيقة الفرضية | حقيقة الفرضية | ||
| صحيحة | خاطئة | ||
| نوع القرار | رفض الفرضية | قرار خاطئ، خطأ من النوع الأول α | قرار صائب |
| نوع القرار | يفشل في رفضها | قرار صائب | قرار خاطئ، خطأ من النوع الثاني β |
يتضح من هذا الجدول أنه يوجد نوعين من الأخطاء التي يمكن أن يرتكبها الباحث عند اختبار الفرضيات الإحصائية، وهما:
1. خطأ من النوع الأول
الخطأ من النوع الأول هو الخطأ الذي يرتكبه الباحث عندما يتخذ قرارًا برفض الفرضية الصفرية وهي في حقيقة الأمر فرضية صحيحة، ويشار لهذا الخطأ بالرمز ألفا (α).
2. خطأ من النوع الثاني
الخطأ من النوع الثاني هو الخطأ الذي يرتكبه الباحث عندما يفشل في رفض الفرضية الصفرية وهي في حقيقة الأمر فرضية خاطئة، ويشار لهذا الخطأ بالرمز بيتا (β).
العلاقة بين النوعين من الخطأ في اختبار الفرضية
العلاقة بين النوعين من الخطأ هي علاقة أخذ وعطاء، فإذا حاول الباحث تقليل الخطأ من النوع الأول فإنه يزيد بذلك من الخطأ من النوع الثاني.
ليس من السهل أن يحدد الباحث أي الخطأين أهم من الآخر، ولكن الباحث يهمه أن تكون قيمة الخطأين أقل ما يمكن. فهو يحاول أن يزيد قوة الاختبار أي يزيد من احتمال الفشل في رفض الفرضية عندما تكون صحيحة، بمعنى زيادة القيمة (1- β)، أما بالنسبة للخطأ من النوع الأول فيمكن للباحث أن يفسح المجال لنفسه باحتمال معين للوقوع بخطأ من هذا النوع. كأن يختار لنفسه 0.05 أو 0.01 (وهي القيم الأكثر شيوعًا) أو غير ذلك من القيم التي تأخذ بالاعتبار مدى خطورة زيادة الخطأ من النوع الثاني بالنسبة لمشكلة البحث.
مستوى الدلالة الإحصائية
مستوى الدلالة الإحصائية أو (بالإنجليزية: Significance Level) هو احتمال وقوع الباحث بخطأ من النوع الأول.
لتوضيح المقصود بمستوى الدلالة الإحصائية فيما يلي المثال التوضيحي التالي:
نفرض أن الفرضية الصفرية للبحث تنص على أن نسبة ذكاء سكان بلد معين أعلى من العادي، وأن الباحث اختار لهذا الفرض عينة من الأفراد وقاس نسبة ذكاؤهم باختبار مقنن للذكاء وكان متوسط نسبة ذكاء أفراد العينة 105 مثلا، فإذا كانت نسبة الذكاء تتوزع توزيعًا اعتداليًا بمتوسط = 100 فإن المتوسط الحسابي للعينة أعلى رقميًا من المتوسط الحسابي العادي بفرق يساوي 5 نقاط.
ولكن السؤال هو فيما إذا كان هذا الفرق نتيجة للصدفة أو لخطأ العينة أم أنه فرقًا حقيقيًا أي أنه فرق دال إحصائيًا؟
للإجابة على هذا السؤال فإن الباحث يحدد منطقة وقوع إحصائي العينة (وهو هنا المتوسط الحسابي) بالنسبة لاحتمال الخطأ الأول، فإذا وقع متوسط نسبة الذكاء المحسوب للعينة في منطقة الخطأ المسموح به (مستوى دلالة 0.05)، بمعنى أن الخطأ الذي وقع فيه الباحث أقل من خطأ الصدفة وأن الفرق دال إحصائيًا. أما إذا كان الخطأ الذي وقع فيه الباحث أعلى من الخطأ الذي سمح به لنفسه (مستوى دلالة 0.01) أي أنه أعلى من خطأ الصدفة، وأن الفرق غير دال إحصائيًا.
تجدر الملاحظة هنا أن الحصول على فرق ذو دلالة إحصائية لا يعتمد فقط على مستوى الدلالة الذي يحدده الباحث ولكن على عوامل أخرى مثل قيمة الإحصائي المحسوب وحجم العينة، والخطأ العيني وسيتضح ذلك في خطوات اختبار الفرضيات.
منطقة الرفض والقيمة الحرجة
يحدد الباحث منطقة الرفض أولا قبل اتخاذه القرار برفض الفرضية الصفرية أو عدم رفضها. ولتحديد هذه المنطقة لا بد وأن يحدد أولا مستوى الدلالة ودرجات الحرية ونوع التوزيع للإحصائي مدار البحث أو الدراسة. لأن هذا التحديد يمكنه من معرفة القيمة الحرجة أو القيم الحرجة. فإذا كانت الفرضية الصفرية غير متجهة فإن منطقة الرفض تقع في طرفي التوزيع وأن لكل طرف قيمة حرجة، أما إذا كانت الفرضية متجهة فإن منطقة الرفض تقع في أحد طرفي التوزيع وذلك حسب صياغة الفرضية البديلة.
خطوات اختبار الفرضيات الإحصائية
فيما يلي الخطوات التي يتخذها الباحث من أجل اختبار الفرضيات الإحصائية:
1. صياغة الفرضية الصفرية (ف.)، والفرضية البديلة (ف1) ولصياغة هاتين الفرضيتين فإنه يلزم تحديد القيمة الفرضية لإحصائي المجتمع حيث تقدر هذه القيمة عادة من خلال الدراسات السابقة التي يرجع إليها الباحث في موضوع بحثه أو دراسته. ومن خلال الإطار النظري له أيضًا.
2. تحديد القيمة المقابلة للإحصائي مدار البحث في العينة حيث يحسب من البيانات الإحصائية المتوفرة أو التي يتم جمعها من قبل الباحث باستخدام أدوات البحث العلمي المناسبة للغرض.
3. تحديد نوع التوزيع الذي يناسب الإحصائي مدار البحث، كأن يكون توزيع Z أو t أو F أو كا2. حيث يعتمد ذلك على نوع الإحصائي، ومدى تحقيق الافتراضات التي يقوم عليها إحصائي معين، وحجم العينة أو درجات الحرية.
4. حساب الخطأ المعياري للتوزيع، حيث يعتمد ذلك على نوع المقارنة التي يجريها الباحث كأن يقارن إحصائي عينة واحدة بإحصائي المجتمع. أو مقارنة إحصائي عينة بالإحصائي نفسه في عينة أخرى، أو المقارنة من عدة عينات.
5. حساب قيمة الاختبار الإحصائي بمعادلة خاصة بالتوزيع ونوع الإحصائي، مثل:
Z = (س – μ) ÷ σ
أو باستخدام برامج الحاسوب الخاصة لحساب قيمة الإحصائي، مثل برنامج SPSS.
6. تحديد مستوى الدلالة الإحصائية (α) أو ما يسمى بالخطأ من النوع الأول، حيث يحدد على ضوئه منطقة الرفض للفرضية الصفرية.
7. إيجاد القيمة الحرجة للإحصائي من الجدول الخاص به، حيث تعتمد هذه القيمة على درجة أو درجات الحرية، كما تعتمد على مستوى الدلالة الإحصائية الذي حدده الباحث.
8. مقارنة القيمة المحسوبة بالقيمة الحرجة أو بالقيم الحرجة واتخاذ القرار برفض أو عدم رفض الفرضية الصفرية على ضوء موقع القيمة المحسوبة بالنسبة لمنطقة الرفض.
اختبار الفرضيات لعينة واحدة
يمكن حساب العديد من الإحصائيات من البيانات المتعلقة بالعينة بهدف الاستدلال على الإحصائيات المقابلة في المجتمع، مثل المتوسط الحسابي، التباين، النسبة والارتباط، كما تختلف الاختبارات الإحصائية لاختبار الفرضيات المتعلقة بهذه الإحصائيات. وذلك حسب نوع التوزيع العيني الذي يناسب ذلك الإحصائي. فالمتوسط الحسابي مثلا يمكن اختباره باستخدام الاختبار الإحصائي Z إذا كان التوزيع العيني توزيعًا اعتداليًا تباينه معروف، وفي هذه الحالة لا تعتمد القيمة الحرجة على درجات الحرية لأنه يفترض أن يكون حجم العينة كبير نسبيًا (ن أكبر أو تساوي 30). أما إذا كان حجم العينة صغير نسبيًا وكان التباين في المجتمع غير معروف بل يقدّر من بيانات العينة، فالاختبار المستخدم هو t.
فيما يلي وصفًا تفصيليًا يوضح طرق اختبار الفرضيات لعينة واحدة مع التوضيح بالأمثلة التطبيقية المبسطة:
1. اختبار فرضية المتوسط الحسابي μ بالاختبار الإحصائي Z
نفرض أن المتوسط الحسابي لعدد ساعات مشاهدة التلفزيون من قبل الراشدين يساوي ثلاث ساعات. وبالتالي فإن الباحث أمام ثلاث طرق لصياغة الفرضية الإحصائية هي:
ف. : μ = 3 ، ف1 : μ ≠ 3 (غير متجهة)
أو:
ف. : μ <= 3 ، ف1 : μ > 3 (متجهة)
أو:
ف. : μ => 3 ، ف1 : μ < 3 (متجهة)
الخطوة الأولى:
إن الخطوة الأولى في اختبار الفرضية هي صياغة الفرضية الصفرية والفرضية البديلة بواحدة من الطرق الثلاث حسب خبراته والخلفية النظرية والدراسات السابقة ذات العلاقة بمشكلة البحث أو الدراسة.
الخطوة الثانية:
حساب المتوسط الحسابي لساعات مراقبة التلفزيون من قبل أفراد عينة مختارة من مجتمع الراشدين في منطقة جغرافية معينة، لنفرض أن المتوسط الحسابي = 3.5.
والخطوة الثالثة:
تحديد الاختبار الإحصائي المناسب، فإذا كان عدد أفراد العينة هنا = 130 مثلا فإن العدد كبير نسبيًا وأنه يمكن اعتبار شروط التوزيع Z متوفرة. وبالتالي فإنه يمكن تقدير الانحراف المعياري للمجتمع من العينة. ولنفرض أن الانحراف المعياري المقدّر هنا = 2.3. أما إذا كان الانحراف المعياري في المجتمع معروف فلا داعي للتقدير.
الخطوة الرابعة:
الخطأ المعياري لتوزيع المتوسطات هنا يقدّر من الانحراف المعياري المقدر ( ع ρ) فإذا رمزنا للخطأ المعياري (ع خـ ) فإن:
ع خـ = ع ρ / الجذر التربيعي لعدد أفراد العينة
وفي هذا المثال فإن:
ع خـ = 2.3 / 11.4
أو:
ع خـ = 0.20 مقربًا لرقمين عشريين.
الخطوة الخامسة:
حساب قيمة الاختبار الإحصائي:
Z = (س – μ) ÷ σ
إذا كان σ معروف. حيث س هو المتوسط الحسابي للعينة.
أو:
Z = (س – μ) ÷ (ع ρ / الجذر التربيعي لعدد أفراد العينة)
وهي هنا:
Z = ( 3.5 – 3.0 ) / 0.2 = 2.50
والخطوة السادسة:
اختيار الدلالة الإحصائية (α) وبالطبع فإن نقصان قيمة α يعني زيادة القيمة الحرجة وبالتالي نقصان فرصة رفض الفرضية الصفرية.
الخطوة السابعة:
إيجاد القيمة الحرجة حيث يعتمد على قيمة α فإن درجات الحرية لا تتدخل في تحديد القيمة الحرجة، وأن العامل المؤثر هنا هو مستوى الدلالة. وبالطبع فإن صياغة الفرضية من حيث كونها متجهة أو غير متجهة تؤثر أيضًا على القيمة الحرجة كما هو مبين في القيم التالية:
| صياغة الفرضية | متجهة | غير متجهة |
| α = 0.01 | 2.33 | 2.58 |
| α = 0.05 | 1.65 | 1.96 |
الخطوة الثامنة:
مقارنة القيمة المحسوبة بالقيمة الحرجة واتخاذ القرار الإحصائي بشأن الفرضية الصفرية. وبما أن هذا المثال بقصد التوضيح فلم يتم تحديد صياغة واحدة للفرضية؛ كما أنه لم يتم تحديد قيمة واحدة لمستوى الدلالة.
فإذا كان القرار رفض الفرضية الصفرية فهذا يعني أن الفرق بين المتوسط الحسابي للعينة والمتوسط الحسابي للمجتمع أعلى من أن يُنسب إلى أخطاء في العينة، وإنما يعتبر فرقًا ذو دلالة إحصائية وليس بالضرورة أن يكون فرقًا ذو دلالة عملية.
فإذا كانت الفرضية في هذا المثال متجهة ومستوى الدلالة = 0.01، فإن القرار الإحصائي هو رفض الفرضية الصفرية، بمعنى أن مجتمع الراشدين الذين اُختيرت منهم العينة يشاهدون التلفزيون بمتوسط ساعات أعلى من المتوسط المعروف. وأن الفرق بين 3.50 و3.00 ليس فرق صدفة. أو أن احتمال أن تكون القيمة المحسوبة (3.50) كانت قد جاءت بالصدفة عندما تكون الفرضية الصفرية صحيحة فعليًا هو احتمال أقل من 0.01.
ملاحظة مهمة في حالة الفرضية غير المتجهة
إذا كانت الفرضية غير متجهة فإن الباحث يمكن أن يقوم بخطوة إضافية هي أن يحسب فترة الثقة للإحصائي بالمعادلة التالية:
فترة الثقة = (القيمة المحسوبة للإحصائي) + أو – (القيمة الحرجة) × (الخطأ المعياري للإحصائي)
فإذا كانت:
ف. : μ = 3 ، ف1 : μ ≠ 3 ، α = 0.05
فإن :
فترة الثقة = 3.5 + أو – (1.96)(0.20)
فترة الثقة = 3.5 + أو – 0.392
ويمكن أن تكتب بالصورة التالية:
3.89 <= μ <= 3.12
بمعنى أننا على ثقة بمقدار 95 % بأن هذا المدى يحتوي على أو يتضمن المتوسط الحسابي للمجتمع.
2. اختبار فرضية المتوسط الحسابي (μ) بالاختبار t
الفرق بين الاختبار Z والاختبار t هو الأثر الناتج عن صغر حجم العينة، حيث يتدخل هذا الحجم في قيمة الخطأ المعياري، وبالتالي القيمة المحسوبة للاختبار الإحصائي. كما يتدخل في إيجاد القيمة الحرجة من خلال درجات الحرية.
يوضح المثال التالي خطوات اختبار الفرضية الإحصائية للمتوسط الحسابي باستخدام الاختبار t.
نفرض أن الدراسات تشير بأن المتوسط الحسابي العادي لاتساع الذاكرة الرقمية لا يزيد عن تسعة أرقام، إلا أن ادعاء أفراد مجتمع معين بأنهم أعلى من العادي بالنسبة لاتساع الذاكرة الرقمية، ولهذا الغرض قام باحث باختيار عينة من 23 فردًا من المجتمع، وقاس اتساع الذاكرة الرقمية لكل فرد منهم. وكانت نتائج العينة تشير إلى أن المتوسط الحسابي لتوزيع اتساع الذاكرة الرقمية في العينة = 9.4 بانحراف معياري = 1.3 وبناء على ذلك فإنه يمكن تلخيص إجراءات اختبار الفرضية بالخطوات التالية:
1. ف. : μ <= 9 ، ف1 : μ > 9
2. حساب قيمة t = (المتوسط الحسابي المحسوب – المتوسط الحسابي المُعطى) ÷ ((الانحراف المعياري) × (الجذر التربيعي لعدد العينة))
t = (9.4 – 9) / ((1.3) * (4.79))
t = 1.475
مقربًا لثلاث أرقام عشرية.
3. القيمة الحرجة للاختبار t على مستوى دلالة 0.05 ودرجات حرية = 22 هي 1.717 (من الجدول).
4. بما أن القيمة المحسوبة أقل من القيمة الحرجة فإن نتائج العينة لا تمكن الباحث من رفض الفرضية الصفرية، وأن ارتفاع المتوسط الحسابي بمقدار (0.4) عن المتوسط الحسابي العادي جاء نتيجة الصدفة وأنه ليس ذو دلالة إحصائية.
3. اختبار فرضية التباين σ2
قلما نجد اهتمامًا لدى الباحثين في اختبار فرضيات حول التباين كمقياس تشتت لمجموعة واحدة، إلا أن اختبار هذا النوع من الفرضيات يساعد عادة في تفسير البيانات الإحصائية التي تكشف في البحوث التربوية والنفسية عن الفروق الفردية، وبشكل خاص عند استخدام الاختبارات المقننة. من المعروف مثلا أن اختبار نسبة الذكاء عند الأفراد على اختبار بينية تتوزع اعتداليًا بتباين = 256، ولكن هل هذا الاختبار قادر على كشف الفروق الفردية في نسبة الذكاء عند أفراد مجتمع معين بنفس المستوى الذي جاء في دليل الاختبار.
نفرض أن باحثًا طبق هذا الاختبار على عينة من 28 فردًا من أفراد مجتمع الدراسة وتبين أن التباين في العينة ع2 = 236، والسؤال هنا هو: هل جاءت عينة البحث أو الدراسة من مجتمع آخر يختلف عن مجتمع التقنين؟
وتتطلب الإجابة عن هذا السؤال اختبار الفرضية:
ف. : σ2 = 256 مقابل ف1 : σ2 ≠ 256
التوزيع العيني للتباين هو كا2، ولذلك فإن الخطوة التالية لاختبار الفرضية هي حساب قيمة الاختبار الإحصائي كا2 بالمعادلة:
كا2 = (ن-1) × ع2 ÷ أ
كا2 = (28-1) × 236 ÷ 256 = 24.89
فإذا اختبرت الفرضية على مستوى دلالة 0.10 وكانت غير متجهة فإن القيم الحرجة تختلف هنا عن القيم الحرجة في توزيع Z و t وذلك لأن توزيع كا2 غير متماثل كما أنه لا توجد قيم سالبة ولذلك فإن جدول كا2 يعطي قيمتين حرجتين الأولى عند احتمال 0.95 والثانية عند احتمال 0.05 لدرجات حرية = 27، وهي في هذا المثال 40.11، 16.15.
وحتى تكون قيمة كا2 دالة إحصائيًا فأنه إما أن تكون القيمة المحسوبة أعلى من 40.11 أو أقل 16.15.
ولذلك فإن القرار الإحصائي هنا هو عدم رفض الفرضية الصفرية بمعنى أن تباين العينة لا يختلف عن تباين المجتمع الذي قنن عليه اختبار الذكاء. وأن اختلاف تباين العينة عن تباين المجتمع جاء بالصدفة، أو أنه غير دال إحصائيًا.
4. اختبار فرضية التوافق بين التكرار الملاحظ والتكرار المتوقع
يتضح من الحديث عن أنواع التوزيعات بأن الإحصائي كا2 إحصائي غير معلمي (بالإنجليزية: Non Parametric) وأنه يستخدم في اختبار عدة فرضيات لبيانات واقعة على المقياس الاسمي من بينها فرضية التوافق بين التكرار الملاحظ (ت) والتكرار المتوقع (تم) الذي يرتكز عادة على خلفية نظرية محددة وليس له علاقة بالبيانات التجريبية. وتوضح المعادلة التالية العلاقة بين الإحصائي كا2 والتكرار، المتوقع والملاحظ.
كا2 = Σ ك (ت – تم )2 / تم
حيث Σ ك = مجاميع من 1 إلى ك، ك = عدد الفئات.
مثال: إذا كان من المتوقع أن تكون نسبة من يؤيدون قرارًا تربويًا في مجتمع ما تساوي نسبة المعارضون ومساوية أيضًا لنسبة الحياديون. فإذا تم اختيار عينة من 45 فردًا من المجتمع، وبعد أن أُخذت آرائهم كانت النتائج كما هي مبينة في الجدول التالي:
| التكرار الملاحظ (ت) | التكرار المتوقع (تم) |
| 12 | 15 |
| 16 | 15 |
| 20 | 15 |
ف. : ت = تم
ف1 : ت ≠ تم
α = 0.05 (مثلا)
درجات الحرية = عدد الفئات (ك) – 1 = 3 – 1 = 2
كا2 الحرجة = 5.99
كا2 المحسوبة = (12-15)2 ÷ 15 + (16-15) 2 ÷ 15 + (20-15)2 ÷ 15
أو
كا2 المحسوبة = (9+1+25) ÷ 15 = 2.33
القرار الإحصائي: بما أن كا2 المحسوبة > كا2 الحرجة، إذن لا نرفض الفرضية الصفرية.
الاستنتاج: نسبة الأفراد المؤيدون أو المحايدون بالنسبة لقرار تربوي معين تتفق مع النسبة المتوقعة. وأن الفروق ناتجة عن التذبذب العشوائي.
اختبار الفرضيات لعينتين
اختبار الفرضيات لعينتين صورة موسعة عن اختبار الفرضيات لعينة واحدة. ولتوضيح ذلك يمكن ملاحظة الفرضيات الصفرية لعينة واحدة لبعض الإحصائيات والفرضيات الصفرية المقابلة لها لعينتين:
| لعينتين | لعينة واحدة | الإحصائي |
| ف. : μ1 = μ2 | ف. : μ = μ. | M |
| ف. : ل1 = ل2 | ف. : ل = ل. | ل |
| ف. : ρ1 = ρ2 | ف. : ρ = 0 | Ρ |
| ف. : σ12= σ22 | ف. : σ2 = ا | σ2 |
ولذلك فإن خطوات اختبار الفرضيات لعينتين هي نفس الخطوات لعينة واحدة، إلا أن الفروق تكمن في كيفية استخراج الخطأ المعياري ودرجات الحرية لأننا نتعامل مع توزيع عيني للفروق. كما أن تطبيق هذه الخطوات يشترط تحقق افتراضين هما:
1. الاستقلالية
أي استقلالية اختيار إحدى العينتين عن الأخرى سواء كنا نتكلم عن العينتين في المجموعة الضابطة والمجموعة التجريبية أو عن عينتين من مجتمعين مختلفين وهذا بمكن توفيره بالاختيار العشوائي والتعيين العشوائي. أما إذا لم تتوفر الاستقلالية فإن هذا سيؤثر على كيفية حساب الخطأ المعياري ودرجات الحرية وبالتالي على القيمة الحرجة ونوع القرار الإحصائي.
2. تجانس التباين
بمعنى أن يكون تباين المجتمع الأول يساوي إحصائيًا تباين المجتمع الثاني، فإذا تحقق هذا الافتراض فإن تباين توزيع الفروق يقدّر بطريقة تختلف عن تقدير نفس الإحصائي عندما لا يتحقق الافتراض نفسه. وبشكل عام فإن مدى تأثير عدم تحقيق افتراض تجانس التباين يعتمد على مدى اختلاف العينات في حجومها.
وسيتضح في اختبار الفرضيات لعينتين المعالجات الإحصائية التي تناسب تحقق هذه الافتراضات وعدم تحققها.
فيما يلي وصفًا تفصيليًا يوضح طرق اختبار الفرضيات لعينتين مع التوضيح بالأمثلة التطبيقية المبسطة:
1. اختبار فرضية تجانس التباين لعينات مستقلة
تبين من الحديث عن توزيع F أنه الإحصائي المناسب لاختبار تجانس التباين. ومما تجدر الإشارة إليه هنا أن الإحصائي F هو النسبة بين تباينين ولذلك فإن اختبار تجانس التباين المشار إليه بالفرضية الصفرية ف.: σ12= σ22 يتم بقسمة التباين الأكبر على التباين الأصغر ومقارنة الناتج بالقيمة الحرجة.
قد يكون اختبار فرضية تجانس التباين هدفًا بحد ذاته وخاصة عندما يتساوى توزيعان بمقاييس النزعة المركزية ويختلفان بمقاييس التشتت، أو أن يكون خطوة مكملة لاختبار فرضية المتوسط الحسابي لعينتين.
مثال تطبيقي
نفرض أن باحثًا اختار عينة من 80 فردًا عشوائيًا وقسمها عشوائيًا بالتساوي إلى مجموعتين (تجريبية وضابطة)، إلا أنه بعد انتهاء المعالجة التجريبية كان الإهدار في المجموعة التجريبية أعلى منه في المجموعة الضابطة، وبعد تطبيق أداة القياس للمتغير التابع حصل على البيانات الإحصائية التالية:
ن1 = 39 ، ن2 = 30
س1 = 85.6 ، س2 = 85.4
ع21 = 78 ، ع22 = 36
يُلاحظ أن أثر المعالجة التجريبية يتضح من خلال التباين كمقياس تشتت وليس من خلال المتوسط الحسابي كمقياس نزعة مركزية.
والسؤال هنا هو: هل هناك تجانس في التباين؟
للإجابة عن هذا السؤال فإن الباحث يسعى إلى اختبار الفرضية التالية:
ف. : σ12= σ22 أو σ12/ σ22 = 1 مقابل الفرضية التالية:
ف. : σ12 ≠ σ22 أو σ12/ σ22 ≠ 1
الخطوة التالية في اختبار الفرضية هي حساب قيمة الاختبار الإحصائي F وذلك بقسمة التباين الأكبر على التباين الأصغر:
F = 78/36 = 2.17
فإذا اُختبرت الفرضية على مستوى دلالة 0.10 مثلا لفرضية غير متجهة، فإن منطقة الرفض تحتل طرفي التوزيع بما يعادل 0.05 من المساحة في كل طرف.
وبما أننا نضع التباين الأكبر على التباين الأصغر فإن F <= 1، وبالتالي فإن منطقة الرفض المقصودة تقع في الطرف الأيمن وأن القيمة الحرجة للاختبار F على درجات حرية 38، 29 هي 1.84.
وبما أن القيمة المحسوبة (2.17) أعلى من القيمة الحرجة (1.84) فإن القرار الإحصائي هو رفض الفرضية الصفرية. بمعنى أن افتراض تجانس التباين لم يتحقق.
ملاحظة
إذا حُسبت قيمة F بقسمة التباين الأصغر على التباين الأكبر فإن القيمة الحرجة في حالة F > 1 هي مقلوب القيمة الحرجة لنفس مستوى الدلالة على درجات حرية معكوسة وهي في هذا المثال = 1/1.77 = 0.565.
حيث 1.77 هي القيمة الحرجة على مستوى دلالة 0.05 ولدرجات حرية 29، 38.
وبما أن القيمة المحسوبة للإحصائي F = 36/78 = 0.462 أقل من القيمة الحرجة فإنها تقع في منطقة الرفض للطرف الأيسر من التوزيع وهذا يؤدي إلى اتخاذ نفس القرار السابق.
2. اختبار فرضية تجانس التباين لعينات غير مستقلة
في حالة تعامل الباحث مع عينات غير مستقلة، فإن الاختبار الإحصائي الذي يناسب توزيع الفروق في التباين هو توزيع t وأن الخطأ المعياري للتوزيع يعتمد على معامل الارتباط بين العينتين، وكل من التباينين.
عدد المشاهدات المزدوجة (حجم العينة) كما في المعادلة التالية:
ع خ ت = الجذر التربيعي لـ (( 4 ع21 × ع22 ) × (1 – ر122) / (ن-2))
ولحساب قيمة الاختبار الإحصائي فإن معادلة التوزيع t تحسب عدد الأخطاء المعيارية للفرق بين التباينين وليس نسبة التباين كما لاحظنا في العينات المستقلة. المعادلة التالية توضح الاختلاف:
t = (ع21 – ع22) / ع خ ت
أما عن القيمة الحرجة فتستخرج من جدول توزيع t عند درجة حرية ن – 2 عند مستوى دلالة يحدده الباحث.
مثال تطبيقي
نفرض أن غرض باحث هو اختبار دلالة الفرض بين تباين علامات عينة من 74 طالب على اختبار السرعة وتباين علاماتهم على اختبار الدقة في الطباعة بعد تعلمهم بطريقة معينة مثل الطريقة السمعية البصرية. فما هو القرار الإحصائي إذا توفرت لديه البيانات التالية:
ر12 = 0.80 ، ع21 = 105 ، ع22 = 82
الفرضية التي يختبرها الباحث هي:
ف. : ع21 = ع22
مقابل:
ف1 : ع21 ≠ ع22
قيمة الاختبار الإحصائي المحسوبة هي:
t = (105-82) / Sqrt (4 * (105) * (82) * (1 – 0.64) / (74-2)) = 1.752
وبما أن القيمة الحرجة للاختبار الإحصائي على مستوى دلالة (0.05 مثلا) لفرضية غير متجهة ولدرجات حرية 72 هي 1.98 وهي أكبر من القيمة المحسوبة فإن القرار الإحصائي هو عدم رفض الفرضية بمعنى أن الفرق غير دال إحصائيًا وأن افتراض تجانس التباين في عينتين غير مستقلتين قد تحقق.
3. اختبار فرضية عدم الاستقلالية
أشرنا في الحديث عن اختبار التوافق بين التكرار الملاحظ والتكرار المتوقع أن الباحث يتعامل مع متغير أسمي بفئتين أو أكثر مثل مؤيد، حيادي، معارض. وأن ما يتوفر لدى الباحث هو التكرار في كل فئة دون النظر إلى أي خاصية أخرى في العينة. ولكن إذا اعتقد الباحث أن نسبة الأفراد في كل فئة تختلف باختلاف الجنس فقد يقرر اختيار عينة من الذكور وعينة من الإناث ليصبح غرض البحث هو الكشف عن مدى اعتماد نوع القرار على الجنس أو بكلام آخر اختبار فرضية عدم الاستقلالية (بالإنجليزية: Test of Independence).
ذكرنا في الحديث عن أنواع التوزيعات بأنه يمكن استخدام الإحصائي كاي تربيع لاختبار عدة فرضيات عندما تقع البيانات على مقياس اسمي، ومن بينها فرضية الاستقلالية. ومن الإجراءات الإحصائية لاختبار الفرضية تبويب البيانات في جدول بالصورة الواردة سابقًا عندما تحدثنا عن معامل ارتباط فاي، ولكن الجدول هنا يمكن أن يتضمن بعدين بمستويين (فئتين) أو أكثر لكل بعد. حيث يشار إليه عادة بجدول التوافق ويسمى المعامل المحسوب في هذه الحالة بمعامل التوافق، ولذلك يعتبر معامل فاي حالة خاصة من معامل التوافق.
يتطلب اختبار فرضية عدم الاستقلالية حساب التكرار المتوقع ثم حساب قيمة كا2 وسنوضح ذلك من خلال المثال المشار إليه سابقًا، وهو مدى علاقة اتجاه أولياء الأمور نحو قرار تربوي بجنس ولي الأمر؛ ويبين الجدول التالي التكرارات المطلوبة بالرموز:
جدول التكرارات
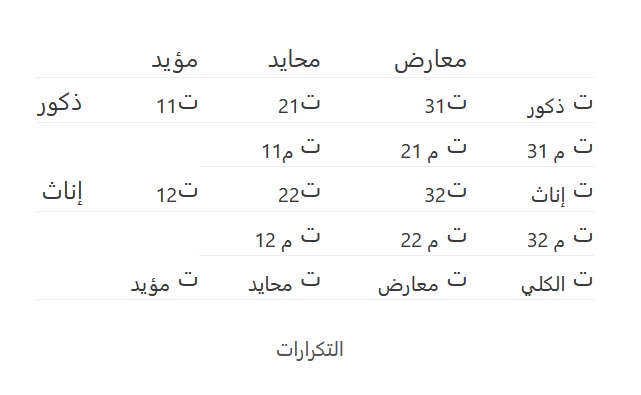
حيث:
ت 11 = التكرار الملاحظ من الذكور المؤيدين
ت م11 = التكرار المتوقع من الذكور المؤيدين = ت ذكور × ت مؤيد / ت الكلي
وهكذا بالنسبة لباقي الرموز في الجدول.
ما يتوفر لدى الباحث أولا هو التكرار الملاحظ، ومن التكرارات الملاحظة يحسب التكرارات المتوقعة.
فإذا كان عدد الأفراد في العينة 75 فردًا موزعة كما في الجدول التالي:
| معارض | محايد | مؤيد | ||
| 45 | 20 | 15 | 10 | ذكور |
| (18) | (12) | (15) | ||
| 30 | 11 | 6 | 13 | إناث |
| (12) | (8) | (10) | ||
| 75 | 30 | 20 | 25 |
وكانت مشكلة الباحث هي في الإجابة عن السؤال التالي:
هل يعتمد اتجاه الأفراد في المجتمع نحو قرار تربوي معين على جنسهم؟
أو بمعنى آخر، اختبار الفرضية الصفرية التالية:
ف. : الاتجاه نحو القرار لا يعتمد على الجنس ( أي أن المتغيرين مستقلين) على مستوى الدلالة (0.05 مثلا)
درجات الحرية (د.ح) = ( ك1 – 1 ) + ( ك2 – 1 ) = (2-1) + (3-1)
درجات الحرية (د.ح) = 3
فإن:
كا2 المحسوبة = 25/15 + 9/12 + 4/18 + 9/10 + 4/10 + 1/12
أو:
كا2 المحسوبة = 1.9
وأن:
كا2 الحرجة = 7.815
وبالتالي فإن القرار الإحصائي هو:
بما أن كا2 المحسوبة > كا2 الحرجة فهذا يعني عدم رفض الفرضية الصفرية بمعنى أن المتغيرين مستقلين فعلا وأن اتجاه الفرد نحو القرار التربوي لا يعتمد على جنسه.
المراجع
- كتاب مهارات البحث العلمي، د.م. مصطفى فؤاد عبيد، مركز البحوث والدراسات متعدد التخصصات، الطبعة الثانية، إسطنبول، تركيا، 2022م.
