ما هو التحليل التمييزي
يستخدم التحليل التمييزي Discriminant Analysis لنمذجة قيمة المتغير الفئوي التابع dependent categorical variable على أساس علاقته بواحد أو أكثر من المتنبئين predictors.
استخدام التحليل التمييزي لتقييم مخاطر الائتمان
إذا كنت مسؤول القروض في أحد البنوك، فأنت تريد أن تكون قادرًا على تحديد الخصائص التي تدل على الأشخاص الذين من المحتمل أن يتخلفوا عن سداد القروض، وتريد استخدام هذه الخصائص لتحديد مخاطر الائتمان الجيدة والسيئة.
افترض أن المعلومات المتعلقة بـ 850 عميلًا سابقًا ومحتملًا موجودة في ملف bankloan.sav. راجع موضوع “ملفات الأمثلة” للحصول على مزيد من المعلومات. أول 700 حالة هم العملاء الذين حصلوا على قروض في السابق. استخدم عينة عشوائية من هؤلاء العملاء البالغ عددهم 700 لإنشاء نموذج تحليل تمييزي Discriminant Analysis، وقم بوضع العملاء المتبقين جانبًا للتحقق من صحة التحليل. ثم استخدم النموذج لتصنيف 150 عميلاً محتملاً باعتبارهم ذوي مخاطر ائتمانية جيدة أو سيئة.
تحضير البيانات للتحليل
يسمح لك إعداد مولد الأعداد العشوائية random seed بتكرار الاختيار العشوائي للحالات في هذا التحليل.
1. لتعيين مولد الأعداد العشوائية، اختر من القوائم: التحويل> مولدات الأرقام العشوائية …
Transform > Random Number Generators…
يظهر مربع حوار مولدات الأرقام العشوائية كما يلي:
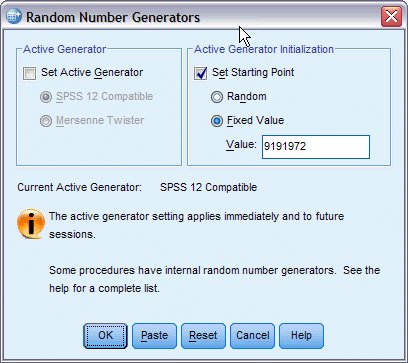
2. حدد تعيين نقطة البداية Set Starting Point.
3. حدد القيمة الثابتة Fixed Value واكتب 9191972 كقيمة.
4. انقر فوق موافق OK.
5. لإنشاء متغير التحديد للتحقق من الصحة election variable for validation، اختر من القوائم: التحويل> حساب المتغير …
Transform > Compute Variable…
يظهر مربع حوار حساب المتغير كما يلي:

6. اكتب تحقق validate في مربع النص Target Variable.
7. اكتب rv.bernoulli (0.7) في مربع نص التعبير الرقمي Numeric Expression.
هذا يحدد قيم التحقق ليتم إنشاؤها عشوائيًا يتغاير برنولي Bernoulli مع معامل الاحتمال 0.7.
أنت تنوي فقط استخدام التحقق من الصحة مع الحالات التي يمكن استخدامها لإنشاء النموذج؛ أي العملاء السابقين. ومع ذلك، هناك 150 حالة مطابقة للعملاء المحتملين في ملف البيانات.
8. لإجراء الحساب للعملاء السابقين فقط، انقر فوق إذا If.
يظهر مربع حوار “إذا كانت الحالات” If Cases كما يلي:
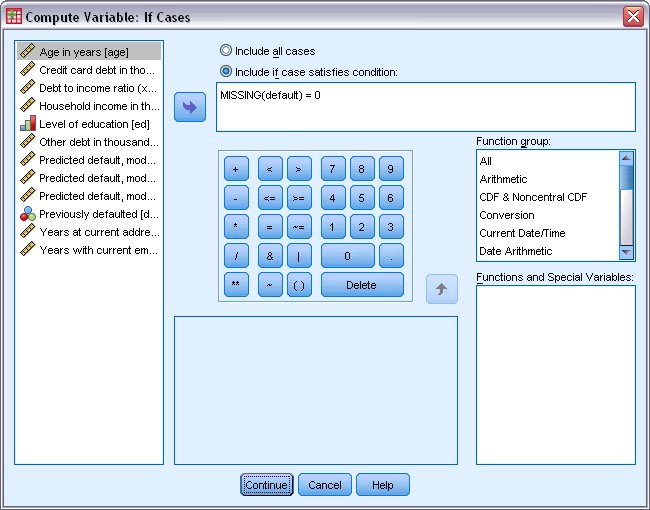
9. حدد تضمين إذا كانت الحالة تفي بالشرط Include if case satisfies condition.
10. اكتب “MISSING(default) = 0” كتعبير شرطي conditional expression.
هذا يضمن أن التحقق من الصحة يتم حسابه فقط للحالات ذات القيم غير المفقودة للافتراضي؛ أي للعملاء الذين سبق لهم الحصول على قروض.
11. انقر فوق متابعة Continue.
انقر فوق “موافق” OK في مربع الحوار حساب المتغير.
ما يقرب من 70 في المائة من العملاء الذين سبق منحهم قروضًا سيكون لديهم قيمة مصدق عليها تبلغ 1. سيتم استخدام هؤلاء العملاء لإنشاء النموذج. سيتم استخدام العملاء المتبقين الذين تم منحهم قروضًا مسبقًا للتحقق من نتائج النموذج.
تشغيل إجراء التحليل التمييزي
1. لتشغيل إجراء التحليل التمييزي، اختر من القوائم: تحليل> تصنيف> تمييز …
Analyze > Classify > Discriminant…
يظهر مربع الحوار الرئيسي لإجراء التحليل التمييزي Discriminant Analysis كما يلي:

2. حدد Previously defaulted كمتغير التجميع أو grouping variable.
3. حدد السنوات مع صاحب العمل الحالي Years with current employer، والسنوات في العنوان الحالي Years at current address، ونسبة الدين إلى الدخل (× 100) Debt to income ratio (x100)، وديون بطاقة الائتمان بالآلاف Credit card debt in thousands كمتغيرات مستقلة independent variables.
4. حدد “التحقق من الصحة” validate كمتغير التحديد أو selection variable.
5. حدد الإعدادات الافتراضية سابقًا Previously defaulted وانقر فوق “تعريف النطاق” Define Range.
يظهر مربع حوار تحديد النطاق Define Range كما يلي:
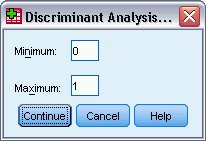
6. اكتب 0 كحد أدنى minimum.
7. اكتب 1 كحد أقصى maximum.
8. انقر فوق متابعة Continue.
9. حدد تحقق validate وانقر على “القيمة” Value في مربع حوار التحليل التمييزي.
يظهر مربع الحوار “تعيين القيمة” كما يلي:
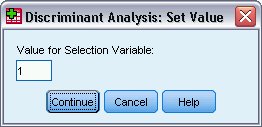
10. اكتب 1 كقيمة لمتغير الاختيار value for selection variable.
11. انقر فوق متابعة Continue.
12. انقر فوق الإحصائيات Statistics في مربع حوار التحليل التمييزي.
يظهر مربع حوار الإحصائيات Statistics كما يلي:

13. حدد Means و Univariate ANOVAs و Box‘s M في مجموعة الوصفي Descriptives.
14. حدد Fisher’s وUnstandardized في مجموعة معاملات الدالة أو Function Coefficients.
15. حدد ارتباط داخل المجموعات Within-groups correlation في مجموعة المصفوفات أو Matrices.
16. انقر فوق متابعة أو Continue.
17. انقر فوق “التصنيف” Classify في مربع حوار التحليل التمييزي.
تحديد التصنيف
يظهر مربع حوار التصنيف أو Classify كما يلي:
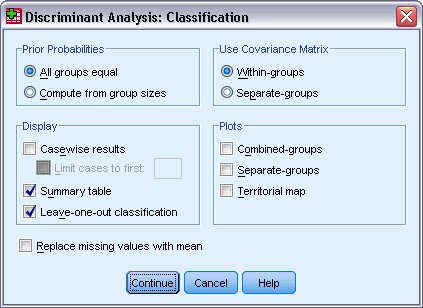
18. حدد جدول الملخص Summary table والتصنيف لمرة واحدة Leave-one-out classification.
19. انقر فوق متابعة Continue.
20. انقر فوق حفظ Save في مربع حوار التحليل التمييزي.
يظهر مربع حوار الحفظ كما يلي:

21. حدد عضوية المجموعة المتوقعة Predicted group membership واحتمالات عضوية المجموعة Probabilities of group membership.
22. انقر فوق متابعة Continue.
23. انقر فوق “موافق” OK في مربع حوار “التحليل التمييزي”.
تصنيف العملاء على أنهم ذوي مخاطر ائتمانية عالية أو منخفضة
الشكل التالي يبين دوال التصنيف أو Classification functions:
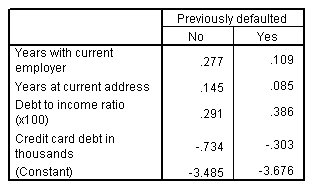
تُستخدم دوال التصنيف لتعيين الحالات إلى المجموعات. هناك دالة منفصلة لكل مجموعة. لكل حالة، يتم حساب درجة التصنيف لكل وظيفة. يعين نموذج التمييز discriminant model الحالة للمجموعة التي حصلت دالة التصنيف الخاصة بها على أعلى الدرجات.
تكون معاملات كل من “السنوات مع صاحب العمل الحالي” Years with current employer و”السنوات في العنوان الحالي” Years at current address أصغر بالنسبة لدالة التصنيف “نعم” Yes، مما يعني أن العملاء الذين عاشوا في نفس العنوان وعملوا في نفس الشركة لسنوات عديدة هم أقل عرضة للتخلف عن السداد. وبالمثل، فإن العملاء الذين لديهم “ديون” debt أكبر هم أكثر عرضة للتخلف عن السداد.
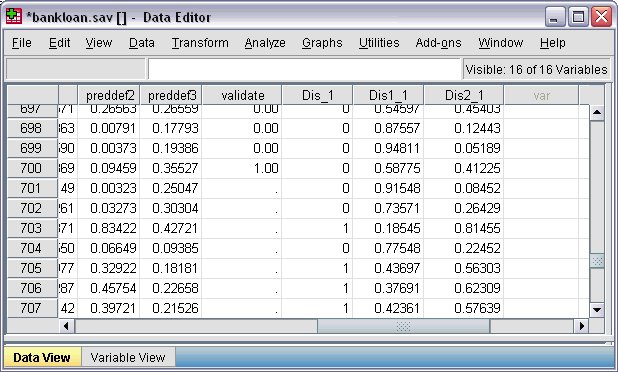
الشكل التالي يبين بيانات الملف Bankloan.sav للحالتين 701 و 703:

على سبيل المثال، ضع في اعتبارك الحالتين 701 و 703. الحالة 701 كان لها نفس صاحب العمل لمدة 16 عامًا، وعاشت في عنوانها الحالي لمدة 13 عامًا، ولديها ديون تعادل 10.9٪ من دخلها، منها 540 دولارًا ديون بطاقة ائتمان.
الشكل التالي يبين الاحتمالات المتوقعة للتقصير في الحالتين 701 و 703:
في الحالة 701، يتنبأ النموذج التمييزي بأن هناك فرصة بنسبة 8٪ فقط للتخلف عن سداد القرض، لذا فهي تمثل مخاطرة ائتمانية جيدة. أما الحالة 703، كان لها نفس صاحب العمل وعاشت في نفس العنوان لسنوات أقل ولديها ديون أكبر، لذلك يعتبرها النموذج مخاطرة ائتمانية غير جيدة.
التحقق من العلاقة الخطية المتداخلة للمتنبئين
الشكل التالي يبين مصفوفة الارتباط داخل المجموعات Within-groups correlation matrix:
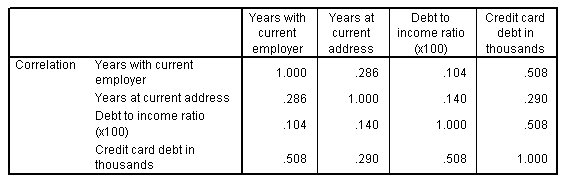
توضح مصفوفة الارتباط داخل المجموعات الارتباطات بين المتنبئين. تحدث أكبر الارتباطات بين “ديون بطاقات الائتمان بالآلاف” Credit card debt in thousands والمتغيرات الأخرى، ولكن من الصعب معرفة ما إذا كانت كبيرة بما يكفي لتكون مصدر قلق. ابحث عن الاختلافات بين مصفوفة البنية structure matrix ومعاملات دالة التمييز discriminant function coefficients للتأكد.
التحقق من ارتباط متوسطات المجموعة والفروق
الشكل التالي يبين إحصائيات المجموعة Group statistics:
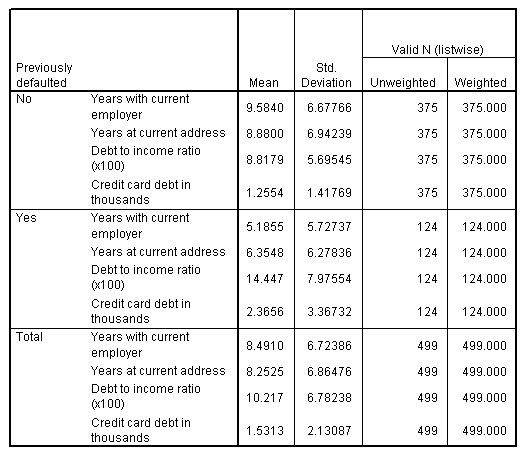
يكشف جدول إحصائيات المجموعة Group statistics عن مشكلة محتملة أكثر خطورة. بالنسبة لجميع المتنبئين الأربعة، ترتبط متوسطات المجموعة الأكبر larger group means بالانحرافات المعيارية للمجموعة الأكبر larger group standard deviations. على وجه الخصوص، انظر إلى نسبة الدين إلى الدخل (× 100) Debt to income ratio (x100) وديون بطاقة الائتمان بالآلاف Credit card debt in thousands، حيث تكون المتوسطات والانحرافات المعيارية للمجموعة “نعم” Yes أعلى بكثير. في مزيد من التحليل، قد ترغب في التفكير في استخدام القيم المحولة transformed values لهذه المتنبئات.
التحقق من تجانس مصفوفات التغاير
الشكل التالي يبين المحددات اللوغاريتمية Log determinants:
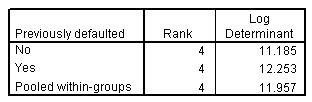
والشكل التالي يبين نتائج الاختبار:

يختبر Box’s M افتراض المساواة في التغاير covariances بين المجموعات. المحددات اللوغاريتمية Log determinants هي مقياس لتقلب المجموعات. المحددات اللوغاريتمية الأكبر تتوافق مع المزيد من مجموعات المتغير. تشير الاختلافات الكبيرة في المحددات اللوغاريتمية إلى المجموعات التي لها مصفوفات تغاير covariance matrices مختلفة.
نظرًا لأن Box’s M مهم، يجب عليك طلب مصفوفات منفصلة لمعرفة ما إذا كانت تعطي نتائج تصنيف مختلفة جذريًا. راجع القسم الخاص بتحديد مصفوفات التغاير المشترك للمجموعات المنفصلة specifying separate-groups covariance matrices لمزيد من المعلومات.
تقييم مساهمة المتنبئين الفرديين
هناك العديد من الجداول التي تقيم مساهمة كل متغير في النموذج، بما في ذلك اختبارات المساواة بين متوسطات المجموعة، ومعاملات الدالة التمييزية، ومصفوفة البنية.
المصدر
- كتاب التحليل الإحصائي باستخدام برنامج SPSS، ترجمة وإعداد: د. م. مصطفى عبيد، مركز البحوث والدراسات متعدد التخصصات، إسطنبول، 2022.
- الموقع الرسمي لشركة IBM ® برنامج SPSS