تحليل الانحدار بطريقة المربعات الصغرى الجزئية
يقدر إجراء الانحدار باستخدام طريقة المربعات الصغرى الجزئية Partial Least Squares Regression نماذج الانحدار للمربعات الصغرى الجزئية (PLS)، وهي تقنية تنبؤية تعد بديلاً لانحدار المربعات الصغرى العادية (OLS)، أو الارتباط الكنسي canonical correlation، أو نمذجة المعادلة الهيكلية structural equation modeling، وهي مفيدة بشكل خاص عندما تكون متغيرات التوقع شديدة الارتباط، أو عندما يتجاوز عدد المتنبئين عدد الحالات.
تجمع طريقة المربعات الصغرى الجزئية PLS بين ميزات تحليل المكونات الرئيسية والانحدار المتعدد multiple regression. تستخرج أولاً مجموعة من العوامل الكامنة التي تشرح أكبر قدر ممكن من التغاير بين المتغيرات المستقلة والتابعة. ثم تتنبأ خطوة الانحدار بقيم المتغيرات التابعة باستخدام تحليل المتغيرات المستقلة.
استخدام انحدار المربعات الصغرى الجزئية في نموذج مبيعات السيارات
تقوم مجموعة صناعة السيارات بتتبع مبيعات مجموعة متنوعة من السيارات الشخصية. في محاولة لتكون قادرًا على تحديد النماذج ذات الأداء العالي والضعيف، فأنت تريد إنشاء علاقة بين مبيعات السيارات وخصائص السيارة.
المعلومات المتعلقة بمختلف أنواع وموديلات السيارات موجودة في ملف car_sales.sav. راجع موضوع “ملفات الأمثلة” للحصول على مزيد من المعلومات. نظرًا لأن خصائص السيارة مترابطة، يجب أن يكون انحدار المربعات الصغرى الجزئية بديلاً جيدًا لانحدار المربعات الصغرى العادية.
تشغيل التحليل
لإجراء تحليل الانحدار بطريقة المربعات الصغرى الجزئية :
اختر من القوائم: تحليل> الانحدار> المربعات الصغرى الجزئية …
Analyze > Regression > Partial Least Squares…
يظهر مربع حوار انحدار المربعات الصغرى الجزئية كما يلي:
2. حدد المبيعات المحولة لوغاريتميًا Log-transformed sales [lnsales] كمتغير تابع dependent variable.
3. حدد المتغيرات من “نوع السيارة” Vehicle type [type] ولغاية “كفاءة استخدام الوقود” Fuel efficiency [mpg] كمتغيرات مستقلة independent variables.
4. انقر فوق علامة التبويب “خيارات” Options.
تظهر علامة التبويب “خيارات” كما يلي:
5. حدد حفظ التقديرات للحالات الفردية Save estimates for individual cases واكتب indvCases كاسم مجموعة البيانات name of the dataset.
6. حدد حفظ التقديرات للعوامل الكامنة Save estimates for latent factors واكتب latentFactors كاسم لمجموعة البيانات.
7. حدد حفظ التقديرات للمتغيرات المستقلة Save estimates for independent variables واكتب indepVars كاسم لمجموعة البيانات.
8. انقر فوق موافق OK.
تفسير نسبة التباين في انحدار المربعات الصغرى الجزئية
الشكل التالي يبين جدول تفسير نسبة التباين Proportion of variance:
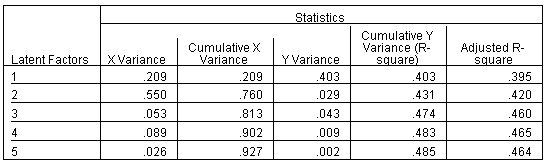
يوضح جدول نسبة التباين الموضح مساهمة كل عامل كامن في النموذج.
- يفسر العامل الأول 20.9٪ من التباين في المتنبئين و 40.3٪ من التباين في المتغير التابع.
- ويفسر العامل الثاني 55.0٪ من التباين في المتنبئين و 2.9٪ من التباين في التابع.
- كما يفسر العامل الثالث 5.3٪ من التباين في المتنبئين و 4.3٪ من التباين في التابع. تفسر العوامل الثلاثة الأولى معًا 81.3٪ من التباين في المتنبئين و 47.4٪ من التباين في المتنبئ.
- على الرغم من أن العامل الرابع يضيف القليل جدًا إلى التباين Y الموضح، إلا أنه يساهم في تباين X أكثر من العامل الثالث، وقيمة R-square المعدلة أعلى من ذلك للعامل الثالث.
- يساهم العامل الخامس في الحد الأدنى من أي عامل في كل من تباين X و Y الموضح، وينخفض R-square المعدل قليلاً. لا يوجد دليل مقنع لاختيار حل من أربعة عوامل على خمسة في هذا الجدول.
مخرجات المتغيرات المستقلة
الشكل التالي يبين جدول المعلمات في انحدار المربعات الصغرى الجزئية:
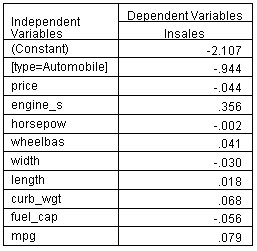
يوضح جدول المعلمات معاملات الانحدار المقدرة لكل متغير مستقل للتنبؤ بالمتغير التابع. بدلاً من الاختبارات النموذجية لتأثيرات النموذج، انظر إلى جدول أهمية المتغير في الإسقاط للحصول على إرشادات حول المتنبئين الأكثر فائدة.
الشكل التالي يبين جدول أهمية المتغير في الإسقاط:
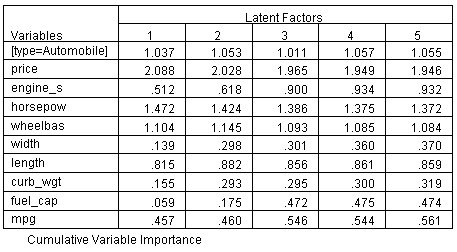
تمثل أهمية المتغير في الإسقاط (VIP) مساهمة كل متنبئ في النموذج، تراكميًا بحسب عدد العوامل في النموذج. على سبيل المثال، في نموذج العامل الواحد، يحمل السعر عبئًا ثقيلًا على العامل الأول وله قيمة VIP تبلغ 2.088. مع إضافة المزيد من العوامل، ينخفض VIP التراكمي للسعر ببطء إلى 1.946، على الأرجح لأنه لا يتم تحميله بشدة على هذه العوامل. على النقيض من ذلك، تمتلك engine_s قيمة VIP 0.512 في نموذج العامل الواحد، والتي ترتفع إلى 0.932 في نموذج العوامل الخمسة.
الشكل التالي يبين جدول مجموعة بيانات المتغيرات المستقلة indepVars:
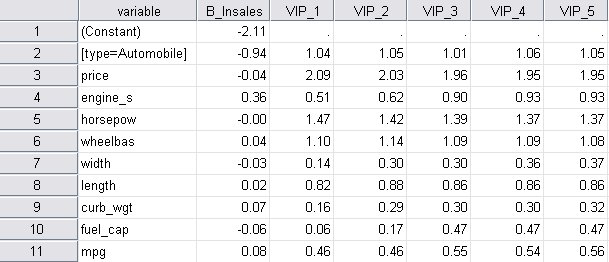
يتم أيضًا حفظ معاملات المعلمات ومعلومات VIP في مجموعة بيانات indepVars ويمكن استخدامها في مزيد من تحليل البيانات. يتم إنشاء مخطط أهمية المتغير التراكمي، على سبيل المثال، باستخدام مجموعة البيانات هذه.
الشكل التالي يبين مخطط أهمية المتغير التراكمي Cumulative variable importance chart:
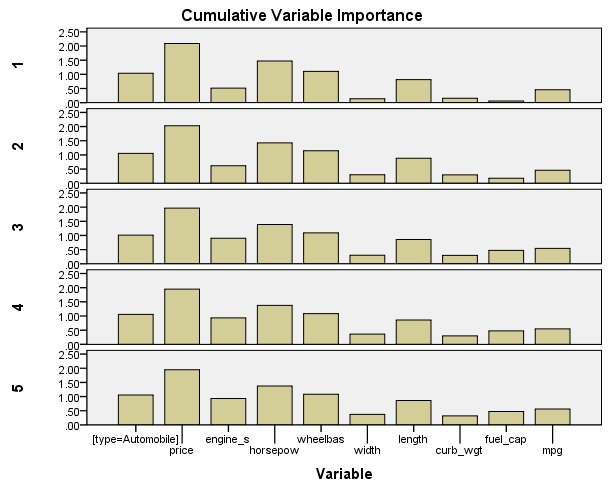
يوفر مخطط أهمية المتغير التراكمي تصورًا لأهمية المتغير في جدول الإسقاط. للحصول على معلومات حول مساهمة المتنبئين في العوامل الفردية بدلاً من النموذج التراكمي، راجع ناتج العوامل الكامنة.
مخرجات العوامل الكامنة
الشكل التالي يبين الأوزان:
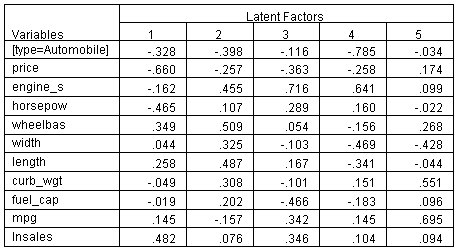
تمثل أوزان المتنبئ الارتباط بين المتنبئين ودرجات Y بواسطة العامل الكامن. وبالمثل، تمثل أوزان المتغير التابع lnsales الارتباط بين درجات lnsales ودرجات X. كما هو متوقع من جدول VIP، يكون وزن السعر أكبر في العامل الكامن الأول وصغير نسبيًا في العوامل الأخرى، بينما يكون وزن المحرك صغيرًا نسبيًا في العامل الأول. ما يتضح من هذا الجدول هو العوامل التي يساهم فيها المحرك بشكل أكبر؛ لها الوزن الأكبر من أي متنبئ على العامل الثالث وثاني أكبر وزن على العامل الرابع. يفسر وزنه الصغير نسبيًا على العامل الخامس الانخفاض الطفيف في الأهمية التراكمية من نموذج العوامل الأربعة إلى نموذج العوامل الخمسة.
الشكل التالي يبين مجموعة بيانات العوامل الكامنة:
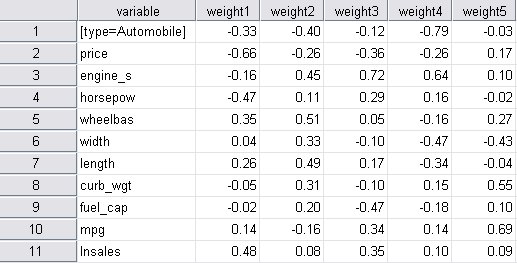
يتم حفظ الأوزان وعمليات التحميل، التي تشبه الأوزان ولن تتم مناقشتها هنا، في مجموعة بيانات العوامل الكامنة ويمكن استخدامها في مزيد من التحليل للبيانات. يتم إنشاء مخططات أوزان العوامل، على سبيل المثال، باستخدام مجموعة البيانات هذه.
الشكل التالي يبين مخطط أوزان العامل 2 مقابل العامل 1:
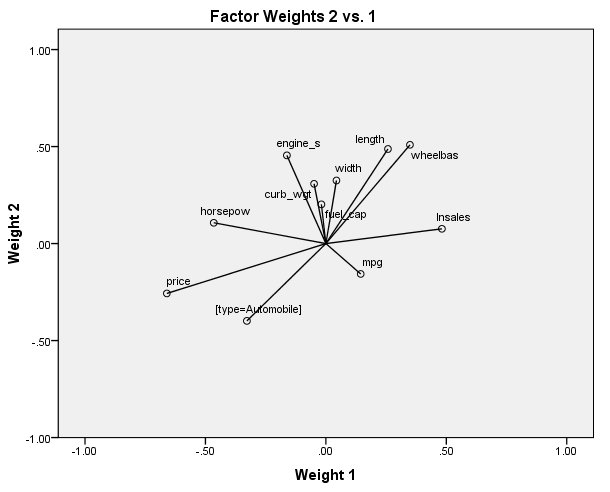
توفر مخططات أوزان العوامل تصورًا للمقارنة الزوجية لأوزان العوامل للعوامل الثلاثة الأولى. في المساحة ثنائية الأبعاد المحددة بواسطة أوزان العاملين الأولين، يمكنك أن ترى أن السعر price والقدرة الحصانية horsepow و (النوع = سيارة) [type = Automobile] يظهران مرتبطين سلبًا بـ lnsales، نظرًا لأنها تشير في اتجاهين متعاكسين. الطول length وقاعدة العجلات wheelbase و mpg مرتبطة بشكل إيجابي إلى حد ما مع lnsales، والآخرون في أحسن الأحوال مرتبطون ارتباطًا ضعيفًا بـ lnsales لأنهم يشيرون بشكل عمودي إلى lnsales.
الشكل التالي يبين مخطط أوزان العوامل 3 مقابل 1:
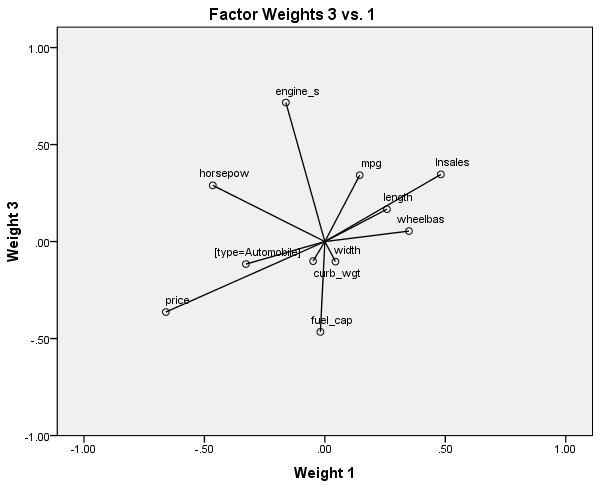
في المساحة المحددة بأوزان العامل 3 و 1، يرتبط متغير fuel_cap، الذي كان مرتبطًا بشكل إيجابي مع engine_s في مخطط العامل 2 مقابل 1، ارتباطًا سلبيًا بالعامل 3.
الشكل التالي يبين مخطط أوزان العامل 3 مقابل 2:
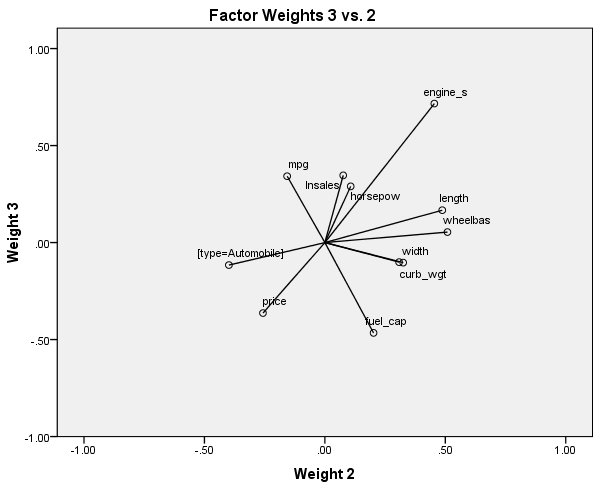
في المساحة المحددة بواسطة أوزان العوامل 3 و 2، يبدو أن lnsales أكثر ارتباطًا بقوة مع mpg وengine_s وfuel_cap مقارنة بالمخططات السابقة، مما يوضح أهمية وجهات النظر المتعددة.
نتائج مخرجات للحالات الفردية
الشكل التالي يبين مجموعة بيانات الحالات الفردية indvCases:
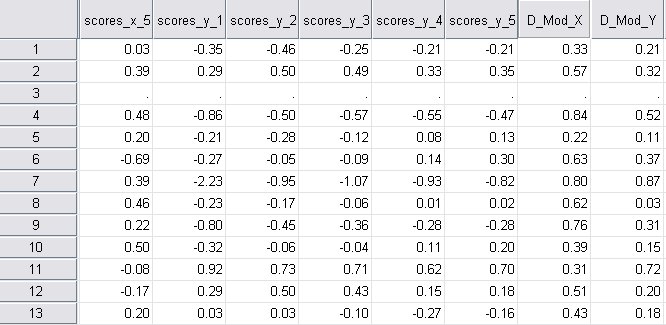
لا يوجد نتائج مجدولة للحالات الفردية؛ ومع ذلك، تتم كتابة ثروة من معلومات الحالة إلى مجموعة بيانات indvCases، بما في ذلك القيم الأصلية للمتغيرات في النموذج، والقيم المتوقعة من النموذج للتنبؤ، والقيم المتوقعة للنموذج لـ lnsales، والحالات المتبقية للتنبؤات والمقاييس، ودرجات X، درجات Y والمسافات X و Y للنموذج (إحصائية PRESS هي ببساطة مجموع مسافات Y المربعة للنموذج). تُستخدم مجموعة البيانات هذه لإنشاء مخطط درجات Y مقابل درجات X ومخطط درجات X مقابل درجات X.
الشكل التالي يبين مخطط درجات Y مقابل درجات X:
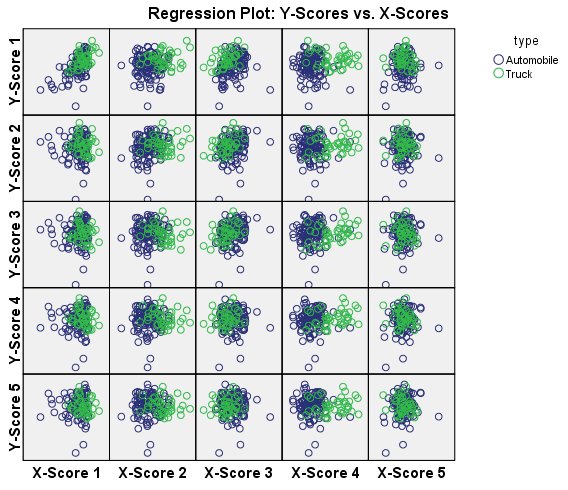
يجب أن تُظهر مصفوفة مخطط الانتشار هذه ارتباطات عالية في أول زوجين من العوامل (المخططات في أعلى يسار المصفوفة)، وتنتشر تدريجيًا إلى القليل جدًا من الارتباط. يمكن أن يكون مفيدًا لتحديد القيم المتطرفة المحتملة لمزيد من التحقيق.
الشكل التالي يبين مخطط درجات X مقابل درجات X:
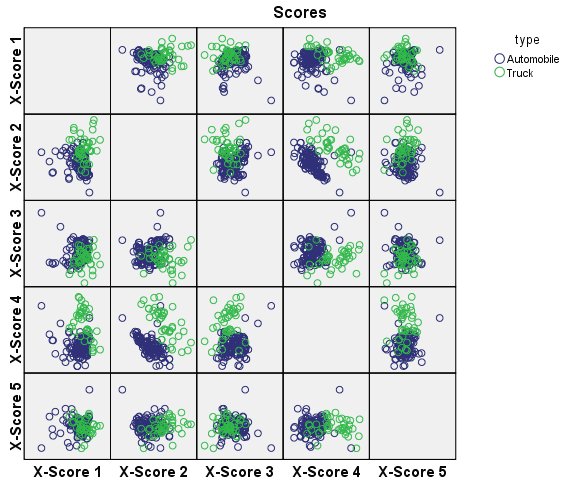
يعد مخطيط درجات X مقابل أنفسهم تشخيصًا مفيدًا. يجب ألا يكون هناك أي أنماط أو مجموعات أو قيم متطرفة Outliers.
- القيم المتطرفة Outliers هي حالات مؤثرة محتملة؛ هناك القليل للتحقيق في هذا المخطط.
- تشير الأنماط والتجمعات إلى نموذج أكثر تعقيدًا، أو قد يكون من الضروري إجراء تحليلات منفصلة للمجموعات. يعد شبه الفصل بين السيارات Automobiles والشاحنات Trucks في X-Score 4 مقلقًا إلى حد ما، خاصة في مخطط X-Score 2 مقابل X-Score 4، حيث يبدو أن المجموعتين تقعان على طول خطوط متوازية. التحليلات المنفصلة للسيارات والشاحنات أمر يجب مراعاته في مزيد من تحليل انحدار المربعات الصغرى الجزئية.
المصدر
- التحليل الإحصائي باستخدام برنامج SPSS، ترجمة وإعداد: د. م. مصطفى عبيد، مركز البحوث والدراسات متعدد التخصصات، إسطنبول، 2022.
- الموقع الرسمي لشركة IBM ® برنامج SPSS