إجراء الانحدار الخطي باستخدام المتغيرات القياسية z-scores
لتشغيل الانحدار الخطي باستخدام المتغيرات القياسية z-scores:
1. قم باستدعاء مربع حوار الانحدار الخطي Linear Regression.
2. قم بإلغاء تحديد المتغيرات من “نوع السيارة” Vehicle type ولغاية “كفاءة استخدام الوقود” Fuel efficiency كمتغيرات مستقلة independent variables.
3. حدد المتغيرات القياسية “نوع السيارة” Zscore: Vehicle type ولغاية “كفاءة استخدام الوقود” Zscore: Fuel efficiency كمتغيرات مستقلة independent variables.
4. انقر فوق موافق OK.
تشخيص العلاقة الخطية المتداخلة
الشكل التالي يبين جدول تشخيص العلاقة الخطية المتداخلة Collinearity diagnostics table، وهو يعرض القيم الذاتية eigenvalues وقيم الفهرس index values. ويظهر فيه اثنين فقط من القيم الذاتية تقترب من الصفر وليس أي من قيم مؤشر الحالة أكبر من 10.
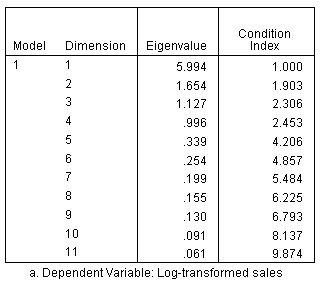
تم تحسين القيم الذاتية eigenvalues وقيم الفهرس index values بشكل كبير بالنسبة للنموذج الأصلي.
الشكل التالي يبين جدول المعاملات، النصف الثاني Coefficients table, second half، وهو يوضح معاملات الارتباطات الصفرية والجزئية والارتباطات الجزئية zero-order, partial and part correlations والتسامح tolerance وVIF كما يلي:
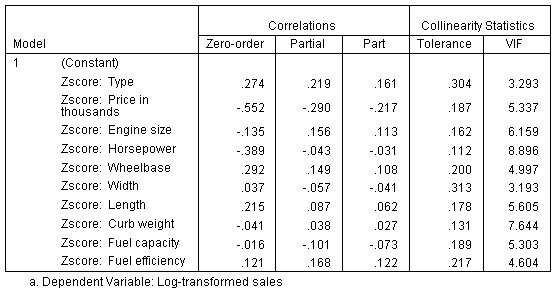
ومع ذلك، لم يتم تحسين إحصائيات العلاقة الخطية المتداخلة التي تم الإبلاغ عنها في جدول المعاملات. هذا لأن تحويل المتغير القياسي z-Score لا يغير العلاقة بين متغيرين. ومثل التشخيص متعدد الخطوط الخطية multicollinearity diagnostic، تكون قيمة الفهرس مفيدة في وضع علامة على مجموعات البيانات التي قد تتسبب في مشاكل في التقدير العددي في الخوارزميات التي لا تعيد قياس المتغيرات المستقلة داخليًا. يحل تحويل z-Score هذه المشكلة، لكننا نحتاج إلى تكتيك آخر لتحسين تضخم التباين. وهو ما سوف يتم فيما يلي.
إجراء الانحدار الخطي باستخدام درجات مكون العامل
في الشكل التالي يبين مربع حوار تحليل العوامل مع تحديد متغيرات z-Score.
باستخدام إجراء تحليل العوامل Factor Analysis، يمكننا إنشاء مجموعة من المتغيرات المستقلة independent variables غير المرتبطة وتتناسب مع المتغير التابع dependent variable وكذلك المتغيرات المستقلة الأصلية original independent variables.
لإجراء التحليل العاملي Factor Analysis على المتغيرات القياسية z-scores:
1. اختر من القوائم: تحليل> تقليل الأبعاد> عاملي …
Analyze > Dimension Reduction > Factor…
2. حدد Zscore: Vehicle type ولغاية Zscore: Fuel efficiency كمتغيرات التحليل analysis variables.
3. انقر فوق استخراج.
يظهر مربع حوار الاستخراج Extraction كما يلي:
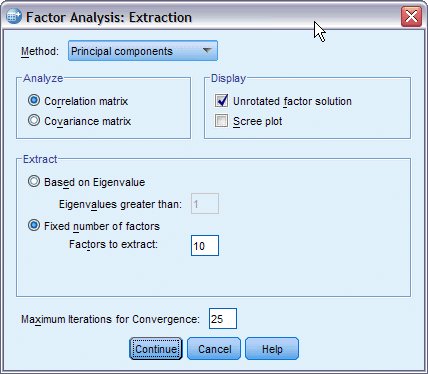
4. في مجموعة استخراج Extract، حدد عددًا ثابتًا من العوامل Fixed number of factors واكتب 10 كعدد العوامل المراد استخلاصها number of factors to extract.
5. انقر على “متابعة” Continue، ثم انقر على “التناوب” Rotation في مربع الحوار “تحليل العوامل”.
يظهر مربع حوار التناوب أو الاستدارة Rotation كما يلي:
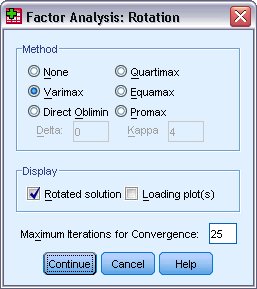
6. في مجموعة الطريقة Method ، حدد Varimax.
7. انقر على متابعة Continue، ثم انقر على الدرجات Scores في مربع حوار تحليل العوامل Factor Analysis.
يظهر مربع حوار درجات العوامل Factor Scores كما يلي:
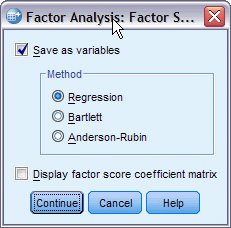
8. حدد حفظ كمتغيرات Save as variables.
9. انقر فوق “متابعة” Continue، ثم انقر فوق “موافق” OK في مربع حوار تحليل العوامل Factor Analysis.
10. لتشغيل الانحدار الخطي باستخدام درجات العوامل factor scores، استرجع مربع حوار الانحدار الخطي Linear Regression.
يظهر مربع حوار الانحدار الخطي Linear Regression، ليتم استخدامه لتحديد متغيرات درجة العامل كمتغيرات مستقلة كما يلي:
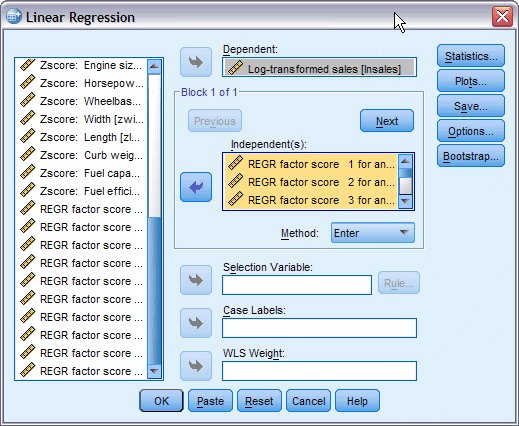
11. قم بإلغاء تحديد Zscore: Vehicle type ولغاية Zscore: Fuel efficiency كمتغيرات مستقلة independent variables.
12. حدد الدرجات من: REGR factor score 1 for analysis 1 [FAC1_1] ولغاية REGR factor score 10 for analysis 1 [FAC10_1] كمتغيرات مستقلة independent variables.
انقر فوق موافق OK.
نتائج التحليل
الشكل التالي يبين جدول ANOVA وهو يوضح مجموع المربعات ودرجات الحرية ومربع المتوسطات و F والدلالة كما يلي:
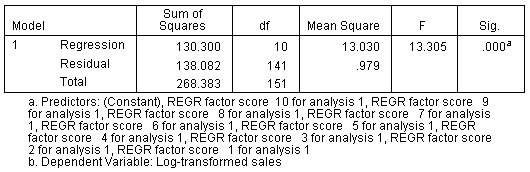
.كما هو متوقع، فإن ملاءمة النموذج هي نفسها بالنسبة للنموذج الذي تم إنشاؤه باستخدام درجات العوامل factor scores كما هو الحال بالنسبة للنموذج باستخدام المتنبئات الأصلية original predictors.
والشكل التالي يبين جدول المعاملات Coefficients table، وهو يُظهر المعاملات غير المعيارية والموحدة (B و Beta)، و t، والدلالة، والارتباطات الصفرية والجزئية والارتباطات الجزئية، والتسامح، و VIF كما يلي:
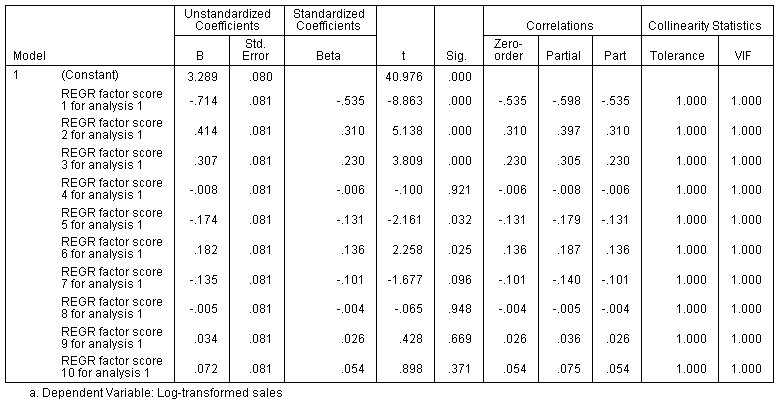
كما هو متوقع أيضًا، تُظهر إحصائيات العلاقة الخطية المتداخلة أن درجات العوامل غير مرتبطة. لاحظ أيضًا أنه نظرًا لأن تباين تقديرات المعامل لا يتم تضخيمه بشكل مصطنع عن طريق العلاقة الخطية المتداخلة، فإن تقديرات المعامل أكبر، بالنسبة إلى أخطائها القياسية standard errors، في هذا النموذج منها في النموذج الأصلي. هذا يعني أنه تم تحديد المزيد من العوامل على أنها ذات دلالة إحصائية، والتي يمكن أن تؤثر على نتائجك النهائية إذا كنت تريد إنشاء نموذج يتضمن تأثيرات مهمة فقط.
المصدر
- التحليل الإحصائي باستخدام برنامج SPSS، ترجمة وإعداد: د. م. مصطفى عبيد، مركز البحوث والدراسات متعدد التخصصات
- الموقع الرسمي لشركة IBM ® برنامج SPSS