الانحدار الترتيبي
يسمح لك إجراء الانحدار الترتيبي Ordinal Regression (المشار إليه باسم PLUM في بناء الجملة) ببناء النماذج، وإنشاء تنبؤات، وتقييم أهمية متغيرات التوقع المختلفة في الحالات التي يكون فيها المتغير التابع (الهدف) ترتيبيًا بطبيعته.
المتغيرات التابعة الترتيبية والانحدار الخطي
عندما تحاول توقع الاستجابات الترتيبية ، فإن نماذج الانحدار الخطي المعتادة لا تعمل بشكل جيد. يمكن أن تعمل هذه الطرق فقط من خلال افتراض أن المتغير الناتج (التابع) يقاس على مقياس الفترة interval scale. نظرًا لأن هذا لا ينطبق على متغيرات النتائج الترتيبية، فإن الافتراضات المبسطة التي يعتمد عليها الانحدار الخطي غير مستوفاة، وبالتالي قد لا يعكس نموذج الانحدار العلاقات في البيانات بدقة. على وجه الخصوص، يكون الانحدار الخطي حساسًا للطريقة التي تحدد بها فئات المتغير المستهدف. مع المتغير الترتيبي ordinal variable، الشيء المهم هو ترتيب الفئات. لذلك، إذا قمت بطي فئتين متجاورتين في فئة واحدة أكبر، فأنت تقوم بإجراء تغيير بسيط فقط، ويجب أن تكون النماذج التي تم إنشاؤها باستخدام التصنيفات القديمة والجديدة متشابهة جدًا. لسوء الحظ، نظرًا لأن الانحدار الخطي حساس للتصنيف المستخدم، فقد يكون النموذج الذي تم إنشاؤه قبل دمج الفئات مختلفًا تمامًا عن النموذج الذي تم إنشاؤه بعده.
النماذج الخطية المعممة
يستخدم النهج البديل تعميمًا للانحدار الخطي يسمى النموذج الخطي المعمم Generalized linear models للتنبؤ بالاحتمالات التراكمية للفئات. باستخدام هذه الطريقة، ستلائم معادلة منفصلة لكل فئة من المتغيرات التابعة الترتيبية. تعطي كل معادلة احتمالية متوقعة للوجود في الفئة المقابلة أو أي فئة أدنى.
على سبيل المثال، انظر إلى التوزيع الموضح في الجدول أدناه. مع عدم وجود تنبؤات في النموذج، تعتمد التنبؤات فقط على الاحتمالات الإجمالية للتواجد في كل فئة. الاحتمال التراكمي المتوقع للفئة الأولى هو 0.80. توقع الفئة الثانية هو 0.80 + 0.07 = 0.87. التنبؤ للثالث هو 0.80 + 0.07 + 0.07 = 0.94، وهكذا. دائمًا ما يكون توقع الفئة الأخيرة 1.0، نظرًا لأن جميع الحالات يجب أن تكون إما في الفئة الأخيرة أو فئة أقل. لهذا السبب، لا حاجة إلى معادلة التنبؤ للفئة الأخيرة.
جدول التوزيع الافتراضي للترتيب التابع:
| Cumulative Probability | Probability of Membership | Category |
| 0.80 | 0.80 | Current |
| 0.87 | 0.07 | 30 days past due |
| 0.94 | 0.07 | 60 days past due |
| 0.99 | 0.05 | 90 days past due |
| 1.00 | 0.01 | Uncollectable |
استخدام الانحدار الترتيبي لبناء نموذج تنبؤ حساب الائتمان
يريد الدائن أن يكون قادرًا على تحديد ما إذا كان مقدم الطلب يمثل مخاطر ائتمانية جيدة، بالنظر إلى الخصائص المالية والشخصية المختلفة. من قاعدة بيانات العملاء، المتغير الدائن (التابع) هو حالة الحساب، مع خمسة مستويات ترتيبية: لا يوجد تاريخ للدين، ولا يوجد دين حالي، ومدفوعات الديون جارية، ومدفوعات الديون التي فات موعد استحقاقها، والحساب الحرج. يتكون المتنبئون المحتملون Potential predictors من الخصائص المالية والشخصية المختلفة لمقدمي الطلبات، بما في ذلك العمر وعدد الائتمانات في البنك ونوع السكن وحالة الحساب الجاري وما إلى ذلك.
يتم جمع هذه المعلومات في ملف german_credit.sav. راجع موضوع “ملفات الأمثلة” للحصول على مزيد من المعلومات. سيتم استخدام إجراء الانحدار الترتيبي لبناء نموذج لتسجيل المتقدمين.
بناء نموذج الانحدار الترتيبي
يتطلب بناء نموذج الانحدار الترتيبي الأولي عدة قرارات. أولاً، بالطبع، تحتاج إلى تحديد متغير النتيجة الترتيبي. بعد ذلك، تحتاج إلى تحديد المتنبئين الذين يجب استخدامهم لمكون الموقع في النموذج. بعد ذلك، عليك أن تقرر ما إذا كنت ستستخدم مكون مقياس scale component، وإذا قمت بذلك، فما هي المتنبئات التي ستستخدمها. أخيرًا، تحتاج إلى تحديد وظيفة الارتباط الأنسب لسؤال البحث وهيكل البيانات.
تحديد متغير النتيجة
في معظم الحالات، سيكون لديك بالفعل متغير هدف محدد في الاعتبار بحلول الوقت الذي تبدأ فيه في بناء نموذج انحدار ترتيبي. بعد كل شيء، سبب استخدامك لنموذج الانحدار الترتيبي هو أنك تعلم أنك تريد توقع نتيجة ترتيبية. في هذا المثال، تكون النتيجة الترتيبية هي حالة الحساب، مع خمس فئات: لا يوجد سجل ديون، ولا يوجد دين حالي، والمدفوعات جارية، والمدفوعات متأخرة، والحساب الحرج.
لاحظ أن هذا الترتيب المعين قد لا يكون، في الواقع، أفضل ترتيب ممكن للنتائج. يمكنك القول بسهولة أن العميل المعروف الذي ليس لديه دين حالي، أو لديه مدفوعات جارية، يعد مخاطرة ائتمانية أفضل من العميل الذي ليس لديه تاريخ ائتماني معروف. راجع المناقشة في اختبار الخطوط المتوازية لمزيد من المعلومات حول هذه المسألة.
اختيار المتنبئين لنموذج الموقع
تشبه عملية اختيار المتنبئين لمكوِّن الموقع في النموذج عملية اختيار المتنبئين في نموذج الانحدار الخطي. يجب أن تأخذ كل من الاعتبارات النظرية والتجريبية في الاعتبار عند اختيار المتنبئين. من الناحية المثالية، سيشمل نموذجك جميع المتنبئين المهمين وليس أيًا من الآخرين. من الناحية العملية، غالبًا ما لا تعرف بالضبط أي المتنبئين سيثبت أهميته حتى تقوم ببناء النموذج. في هذه الحالة، من الأفضل عادةً البدء بتضمين جميع المتنبئين الذين تعتقد أنهم قد يكونون مهمين. إذا اكتشفت أن بعض هذه المتنبئات لا يبدو أنها مفيدة في النموذج، فيمكنك إزالتها وإعادة تقدير النموذج.
في هذا المثال، حددت الخبرة السابقة وبعض التحليلات الاستكشافية الأولية خمسة تنبؤات محتملة: العمر، ومدة القرض، وعدد الائتمانات في البنك، وديون الأقساط الأخرى، ونوع السكن. ستقوم بتضمين هذه المؤشرات في التحليل الأولي ثم تقييم أهمية كل متنبئ. عدد الاعتمادات وديون الأقساط الأخرى ونوع السكن هي مؤشرات فئوية يتم إدخالها كعوامل في النموذج. يعتبر عمر ومدة القرض متنبئين من نوع القياس المتصل، يتم إدخالهما كمتغيرات مشتركة في النموذج.
مكون المقياس
القرار التالي له مرحلتان. القرار الأول هو ما إذا كان سيتم تضمين مكون مقياس Scale Component في النموذج على الإطلاق. في كثير من الحالات، لن يكون مكون المقياس ضروريًا، وسيوفر نموذج الموقع فقط ملخصًا جيدًا للبيانات. من أجل الحفاظ على الأشياء بسيطة، من الأفضل عادةً البدء بنموذج الموقع فقط، وإضافة مكون مقياس فقط إذا كان هناك دليل على أن نموذج الموقع فقط غير مناسب لبياناتك. باتباع هذه الفلسفة، ستبدأ بنموذج الموقع فقط، وبعد تقدير النموذج، حدد ما إذا كان مكون المقياس مضمونًا أم لا.
اختيار دالة الارتباط
1. لاختيار دالة ارتباط Link Function، من المفيد فحص توزيع القيم لمتغير النتيجة. لإنشاء مخطط شريطي لحالة الحساب، اختر من القوائم: الرسوم البيانية> منشئ المخطط …
Graphs > Chart Builder…
يظهر منشئ المخطط Chart Builder كما يلي:
2. حدد معرض الشريطي Bar واختر شريط بسيط Simple Bar.
3. في علامة التبويب خصائص العنصر Element Properties، حدد النسبة المئوية Percentage كإحصائية في مجموعة الإحصائيات Statistics.
4. حدد حالة الحساب Account status كمتغير لرسمه على محور الفئة category axis.
5. انقر فوق موافق OK.
الشكل التالي يبين توزيع القيم لحالة الحساب Account status:
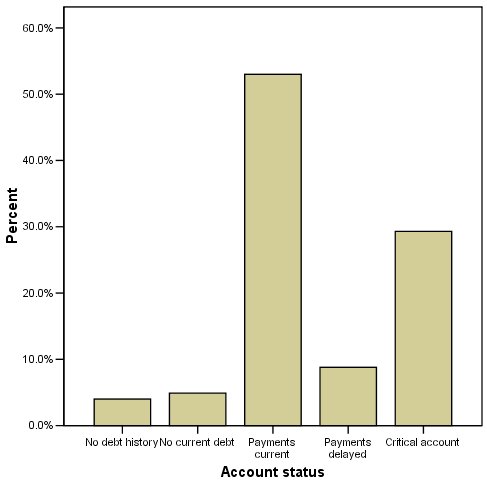
يظهر الرسم البياني الشريطي الناتج توزيع فئات حالة الحساب. الجزء الأكبر من الحالات في الفئات الأعلى، وخاصة الفئات 3 (المدفوعات الحالية) payments current و 5 (الحساب الحرج) critical account. الفئات الأعلى هي أيضًا حيث يوجد معظم “الإجراء” action، نظرًا لأن أهم الفروق من منظور الأعمال هي بين الفئات 3 و4 و5. لهذا السبب، ستبدأ بدالة الارتباط التكميلية complementary log-log link function، حيث تركز هذه الدالة على فئات النتائج الأعلى. يشير العدد الكبير من الحالات في الفئة القصوى 5 (الحساب الحرج) إلى أن توزيع Cauchit قد يكون بديلاً معقولاً.
تشغيل تحليل الانحدار الترتيبي
1. لتشغيل تحليل الانحدار الترتيبي، اختر من القوائم: تحليل> الانحدار> ترتيبي …
Analyze > Regression > Ordinal…
يظهر مربع الحوار الرئيسي لإجراء الانحدار الترتيبي Ordinal Regression كما يلي:
2. حدد حالة الحساب Account status كمتغير تابع dependent variable.
3. حدد عدد الائتمانات الحالية # of existing credits وديون الأقساط الأخرى Other installment debts والسكن Housing كعوامل factors.
4. حدد العمر بالسنوات Age in years والمدة بالأشهر Duration in months كمتغيرات مشتركة covariates.
5. انقر فوق خيارات Options.
يظهر مربع حوار الخيارات كما يلي:
6. حدد الدالة التكميلية Complementary Log-Log كدالة الربط link function.
7. انقر فوق متابعة Continue.
8. انقر فوق المخرجات Output في مربع حوار الانحدار الترتيبي Ordinal Regression.
يظهر مربع حوار المخرجات كما يلي:
9. حدد اختبار الخطوط المتوازية Test of Parallel Lines في مجموعة العرض Display.
10. حدد الفئة المتوقعة Predicted Category في مجموعة المتغيرات المحفوظة Saved Variables.
11. انقر فوق متابعة Continue.
12. انقر فوق “موافق” OK في مربع حوار الانحدار الترتيبي Ordinal Regression.
تقييم نموذج الانحدار الترتيبي
أول شيء تراه في الإخراج هو تحذير بشأن الخلايا ذات التردد الصفري. سبب ظهور هذا التحذير هو أن النموذج يتضمن متغيرات مشتركة متصلة continuous. تعتمد إحصائيات ملائمة معينة للنموذج على تجميع البيانات استنادًا إلى أنماط قيمة المتنبئ والنتائج الفريدة. على سبيل المثال، جميع الحالات التي يكون فيها مقدمو الطلبات لديهم مدفوعات جارية على الديون، وائتمان آخر في البنك، ويمتلكون منزلهم، وليس لديهم ديون أقساط أخرى، يبلغون من العمر 49 عامًا ويسعون للحصول على قرض مدته 12 شهرًا يجتمعون لتشكيل خلية. ومع ذلك، نظرًا لأن المدة بالأشهر والعمر بالسنوات كلاهما متغيرات متصلة continuous، فإن معظم الحالات لها قيم فريدة لتلك المتغيرات. ينتج عن هذا جدول كبير جدًا به العديد من الخلايا الفارغة، مما يجعل من الصعب تفسير بعض إحصائيات الملاءمة. يجب أن تكون حريصًا في تقييم هذا النموذج، لا سيما عند النظر إلى إحصائيات الملائمة المستندة إلى مربع كاي chi-square.
الشكل التالي يبين هذا التحذير بشأن الخلايا الفارغة:

الشكل التالي يبين مربع حوار المخرجات Output:
بالنسبة للنماذج البسيطة نسبيًا مع بعض العوامل، يمكنك عرض معلومات حول الخلايا الفردية عن طريق تحديد معلومات الخلية في مربع حوار المخرجات. ومع ذلك، لا يوصى بذلك للنماذج التي تحتوي على العديد من العوامل (أو العوامل ذات المستويات المتعددة)، أو النماذج ذات المتغيرات المشتركة المتصلة، نظرًا لأن مثل هذه النماذج تؤدي عادةً إلى جداول كبيرة جدًا. غالبًا ما تكون هذه الجداول الكبيرة ذات قيمة محدودة في تقييم النموذج، ويمكن أن تستغرق وقتًا طويلاً لمعالجتها.
القيمة التنبؤية للنموذج
قبل أن تبدأ في النظر إلى المتنبئين الفرديين في النموذج، تحتاج إلى معرفة ما إذا كان النموذج يعطي تنبؤات كافية. للإجابة على هذا السؤال، يمكنك فحص جدول معلومات ملاءمة النموذج Model-Fitting Information table. هنا ترى قيم -2 log-likelihood values للتقاطع فقط (خط الأساس) baseline والنموذج النهائي (مع المتنبئين). في حين أن إحصائيات الاحتمالية log-likelihood statistics نفسها مشكوك فيها نظرًا للعدد الكبير من الخلايا الفارغة في النموذج، لا يزال من الممكن تفسير الاختلاف في احتمالية السجل على أنه إحصائيات موزعة لمربع كاي chi-square. مربع كاي المذكور في الجدول يعبر عن مجرد أن: الفرق بين ضعف احتمالية التسجيل لنموذج التقاطع فقط log-likelihood for the intercept-only model والنموذج النهائي final model، هو ضمن الخطأ التقريبي.
الشكل التالي يبين معلومات ملاءمة النموذج Model-fitting information:
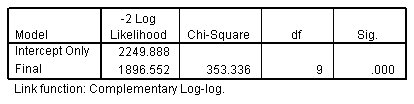
تشير إحصائية مربع كاي إلى أن النموذج يعطي تحسنًا ملحوظًا على نموذج التقاطع الأساسي فقط. يخبرك هذا بشكل أساسي أن النموذج يعطي تنبؤات أفضل مما لو كنت قد خمنت بناءً على الاحتمالات الهامشية لفئات النتائج. هذه علامة جيدة، لكن ما تريد معرفته حقًا هو مدى جودة النموذج.
إحصائيات ملاءمة مربع كاي
الجدول التالي في الإخراج هو جدول Goodness-of-Fit. يحتوي هذا الجدول على إحصائية بيرسون لمربع كاي للنموذج وإحصائية أخرى لمربع كاي بناءً على الانحراف. تهدف هذه الإحصائيات إلى اختبار ما إذا كانت البيانات المرصودة غير متوافقة مع النموذج المناسب. إذا لم تكن كذلك – أي إذا كانت قيم الأهمية كبيرة – فستستنتج أن البيانات وتوقعات النموذج متشابهة وأن لديك نموذجًا جيدًا.
الشكل التالي يبين جدول جودة الملاءمة Goodness-of-fit، يوضح قيم معامل بيرسون للارتباط Pearson وانحراف كاي ودلالاته:

يمكن أن تكون هذه الإحصائيات مفيدة جدًا للنماذج التي تحتوي على عدد صغير من المتنبئين الفئويين. لسوء الحظ، تعتبر هذه الإحصائيات حساسة للخلايا الفارغة. عند تقدير النماذج ذات المتغيرات المشتركة المتصلة، غالبًا ما توجد العديد من الخلايا الفارغة، كما في هذا المثال. لذلك، يجب ألا تعتمد على أي من إحصائيات الاختبار هذه مع هذه النماذج. بسبب الخلايا الفارغة، لا يمكنك التأكد من أن هذه الإحصائيات ستتبع حقًا توزيع مربع كاي، ولن تكون قيم الدلالة دقيقة.
مقاييس R-Squared الزائفة
في نموذج الانحدار الخطي، يلخص معامل التحديد، R-Squared، نسبة التباين في المتغير التابع المرتبط بالمتغيرات المتنبئة (المستقلة)، حيث تشير قيم R-Squared الأكبر إلى أن المزيد من التباين يتم شرحه بواسطة النموذج ، بحد أقصى 1. بالنسبة لنماذج الانحدار ذات المتغير التابع الفئوي، لا يمكن حساب إحصائية R-Squared واحدة تحتوي على جميع خصائص R-Squared في نموذج الانحدار الخطي، لذلك يتم حساب هذه التقديرات التقريبية بدلاً من ذلك. يتم استخدام الطرق التالية لتقدير معامل التحديد.
- يعتمد Cox و Snell’s R-Squared على احتمالية النموذج log likelihood for the model مقارنة باحتمالية النموذج لخط الأساس log likelihood for a baseline model. ومع ذلك، مع النتائج الفئوية، لها قيمة قصوى نظرية أقل من 1، حتى بالنسبة للنموذج “المثالي”.
- Nagelkerke’s R 2 2 هو نسخة معدلة من Cox & Snell R-square التي تعدل مقياس الإحصاء لتغطية النطاق الكامل من 0 إلى 1.
- McFadden’s R 2 3 هو إصدار آخر، يعتمد على log-likelihood kernels لنموذج التقاطع فقط intercept-only model والنموذج التقديري الكامل full estimated model.
ما يشكل قيمة R-Squared “جيدة” يختلف باختلاف مجالات التطبيق. في حين أن هذه الإحصائيات يمكن أن تكون موحية من تلقاء نفسها، إلا أنها مفيدة للغاية عند مقارنة النماذج المتنافسة لنفس البيانات. النموذج الذي يحتوي على أكبر إحصائية لـ R-Squared هو “الأفضل” وفقًا لهذا المقياس.
الشكل التالي يبين قياسات R-Squared الزائفة:

هنا، قيم R-Squared الزائفة محترمة ولكنها تترك شيئًا ما، وهو شيء مطلوب. من المحتمل أن يكون من المفيد مراجعة النموذج لمحاولة عمل تنبؤات أفضل.
جدول التصنيف
الخطوة التالية في تقييم النموذج هي فحص التنبؤات الناتجة عن النموذج. تذكر أن النموذج يعتمد على توقع الاحتمالات التراكمية. ومع ذلك، فإن أكثر ما تهتم به على الأرجح هو عدد المرات التي يمكن أن ينتج فيها النموذج فئات متوقعة صحيحة بناءً على قيم متغيرات التنبؤ. لمعرفة مدى جودة أداء النموذج، يمكنك إنشاء جدول تصنيف – يسمى أيضًا مصفوفة الارتباك – من خلال جدولة الفئات المتوقعة مع الفئات الفعلية. يمكنك إنشاء جدول تصنيف في إجراء آخر، باستخدام الفئات التي تم توقعها بواسطة النموذج المحفوظ. راجع موضوع تحليل تقاطعات البيانات الفئوية باستخدام Crosstabs للحصول على مزيد من المعلومات.
الشكل التالي يبين جدول التصنيف للنموذج الأولي:
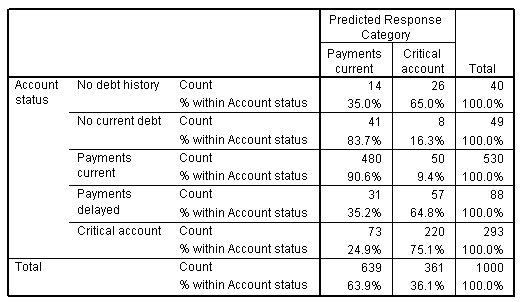
يبدو أن النموذج يقوم بعمل محترم في التنبؤ بفئات النتائج، على الأقل بالنسبة للفئات الأكثر شيوعًا – الفئة 3 (مدفوعات الديون الجارية) debt payments current والفئة 5 (الحساب الحرج) critical account. يصنف النموذج بشكل صحيح 90.6٪ من حالات الفئة 3 و 75.1٪ من حالات الفئة 5. بالإضافة إلى ذلك، من المرجح أن يتم تصنيف الحالات في الفئات 2 على أنها فئة 3 مقارنة بالفئة 5، وهي نتيجة مرغوبة للتنبؤ بالاستجابات الترتيبية.
من ناحية أخرى، فإن حالات الفئة 1 (لا يوجد سجل ائتماني) no credit history يتم التنبؤ بها بشكل سيئ إلى حد ما، حيث يتم تخصيص غالبية الحالات للفئة 5 (الحساب الحرج) critical account، وهي فئة يجب أن تكون نظريًا مختلفة تمامًا عن الفئة 1. وقد يشير هذا إلى وجود مشكلة في الطريقة التي يتم بها تحديد مقياس النتيجة الترتيبي. من أجل الإيجاز، لن تتابع هذه المشكلة أكثر هنا، ولكن في حالة تحليل البيانات الفعلية، قد ترغب في التحقيق في ذلك ومحاولة اكتشاف ما إذا كان المقياس الترتيبي نفسه يمكن تحسينه عن طريق إعادة الترتيب أو الدمج أو استبعاد بعض التصنيفات.
اختبار الخطوط المتوازية
الشكل التالي يبين جدول نتائج اختبار الخطوط المتوازية Test of Parallel Lines:
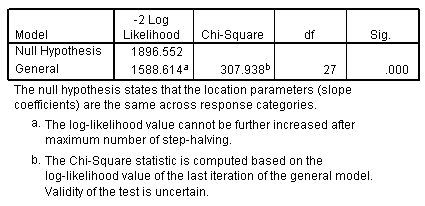
بالنسبة لنماذج الموقع فقط، يمكن أن يساعدك اختبار الخطوط المتوازية في تقييم ما إذا كان افتراض أن المعلمات متماثلة لجميع الفئات أمرًا معقولاً. يقارن هذا الاختبار النموذج المقدر بمجموعة واحدة من المعاملات لجميع الفئات بنموذج بمجموعة منفصلة من المعاملات لكل فئة. يمكنك أن ترى أن النموذج العام (مع معلمات منفصلة لكل فئة) يعطي تحسنًا كبيرًا في ملاءمة النموذج. يمكن أن يكون هذا بسبب عدة أشياء، بما في ذلك استخدام وظيفة ارتباط غير صحيحة أو استخدام نموذج خاطئ.
من الممكن أيضًا أن يكون النموذج السيئ مناسبًا بسبب الترتيب المختار لفئات المتغير التابع. الأمر الذي لا يضع تاريخًا للديون كخطر ائتماني أكبر قد يكون مناسبًا بشكل أفضل. سيكون من المثير للاهتمام أيضًا فحص ملف البيانات هذا باستخدام إجراء الانحدار الترتيبي متعدد الحدود Multinomial Logistic Regression، لأنه يسمح لك بتجنب مشكلات الترتيب ويسمح أيضًا بتأثيرات مختلفة للتنبؤات.
تقييم اختيار دالة الربط
في كثير من الأحيان، لن يكون هناك اختيار نظري واضح لدالة الربط Link Function بناءً على البيانات. في الحالات التي يكون فيها أداء النموذج الأولي ضعيفًا، يجدر عادةً تجربة دوال ارتباط بديلة لمعرفة ما إذا كان يمكن إنشاء نموذج أفضل بدالة ارتباط مختلفة. على الرغم من أن بعض وظائف الارتباط تؤدي أداءً مشابهًا تمامًا في العديد من الحالات (لا سيما دوال logit, complementary log-log and negative log-log functions)، إلا أن هناك مواقف يمكن أن يؤدي فيها اختيار دالة الارتباط إلى إنشاء نموذجك أو فشله.
في هذا المثال، هناك دالتان على الأقل من دوال الربط (complementary log-log and Cauchit) التي قد تكون مناسبة. على الرغم من أن النموذج يعمل بشكل جيد مع complementary log-log link، فقد يكون من الممكن تحسين ملاءمة النموذج باستخدام دالة الربط Cauchit.
يمكنك الآن تقدير نموذج جديد باستخدام دالة ارتباط Cauchit لمعرفة ما إذا كان التغيير يزيد من الفائدة التنبؤية للنموذج. يوصى بالاحتفاظ بنفس مجموعة متغيرات التوقع في النموذج حتى تنتهي من تقييم دوال الارتباط. إذا قمت بتغيير دالة الارتباط ومجموعة المتنبئين في نفس الوقت، فلن تعرف أي منهما تسبب في أي تغيير في ملاءمة النموذج.
مراجعة النموذج
1. قم باستدعاء مربع حوار الانحدار الترتيبي Ordinal Regression.
يظهر مربع حوار الانحدار الترتيبي كما يلي:
2. انقر فوق خيارات Options في مربع حوار الانحدار الترتيبي Ordinal Regression.
3. حدد Cauchit كدالة ربط link function.
4. انقر فوق متابعة Continue.
5. انقر فوق “موافق” OK في مربع حوار الانحدار الترتيبي Ordinal Regression.
معلومات ملاءمة النموذج
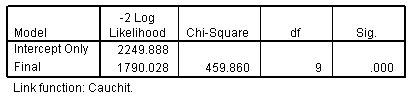
الشكل التالي يبين معلومات ملاءمة النموذج مع دالة الربط Cauchit:
والشكل التالي يبين معلومات ملاءمة النموذج مع دالة الربط التكميلي Complementary log-log:
مستوى الدلالة لإحصاء مربع كاي chi-square أقل من 0.05، مما يشير إلى أن نموذج كاوتشيت Cauchit أفضل من التخمين البسيط. وإحصائية مربغ كاي chi-square لدالة ربط Cauchit كاوتشيت هو (459.860) أكبر من دالة Complementary log-log الربط التكميلي (353.336). يشير هذا إلى أن ارتباط Cauchit أفضل.
مقاييس R-squared الزائفة
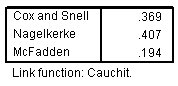
الشكل التالي يبين مقاييس R-squared الزائفة للنموذج مع الربط Cauchit:
والشكل التالي يبين مقاييس R-squared الزائفة للنموذج مع الربط اللوغاريتمي التكميلي Complementary log-log:
تعد الإحصائيات الزائفة r-squared أكبر بالنسبة لارتباط Cauchit من الارتباط اللواغاريتمي التكميلي، مما يشير أيضًا إلى أن ارتباط Cauchit أفضل.
جدول التصنيف
الشكل التالي يبين جدول التصنيف Classification Table للنموذج مع ربط Cauchit:
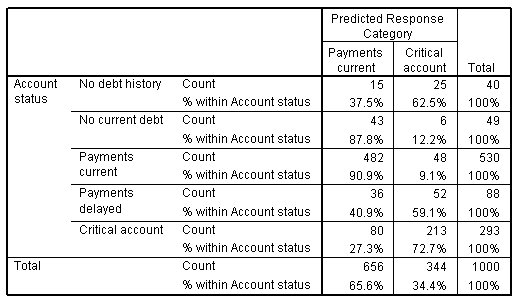
يبدو أن نموذج Cauchit أفضل قليلاً في التنبؤ بالفئات الدنيا (1 و 2 و 3) وأسوأ قليلاً في التنبؤ بالفئات الأعلى من النموذج السابق. نظرًا لأن الهدف الأكثر أهمية لتسجيل الائتمان هو التحديد الصحيح للحسابات التي من المحتمل أن تصبح حرجة (الفئة 5)، فمن المحتمل أن تختار الاحتفاظ بالنموذج اللوغاريتمي التكميلي log-log model، على الرغم من أن إحصائيات الملائمة تفضل نموذج Cauchit.
تفسير النموذج
يلخص جدول تقديرات المعلمات parameter estimates تأثير كل متنبئ. في حين أن تفسير المعاملات في هذا النموذج صعب بسبب طبيعة دالة الارتباط، فإن علامات معاملات المتغيرات المشتركة والقيم النسبية لمعاملات مستويات العامل يمكن أن تعطي رؤى مهمة حول تأثيرات المتنبئين في النموذج.
- بالنسبة للمتغيرات المشتركة covariates، تشير المعاملات الإيجابية (السلبية) إلى علاقات إيجابية (عكسية) بين المتنبئين والنتيجة. تتوافق القيمة المتزايدة للمتغير المشترك ذي المعامل الإيجابي مع احتمال متزايد للوجود في إحدى فئات النتائج التراكمية “الأعلى”.
- بالنسبة للعوامل، يشير مستوى العامل ذي المعامل الأكبر إلى احتمالية أكبر للوجود في إحدى فئات النتائج التراكمية “الأعلى”. تعتمد علامة المعامل لمستوى العامل على تأثير مستوى العامل بالنسبة للفئة المرجعية.
الشكل التالي يبين جدول تقديرات المعلمات للنموذج مع الارتباط اللوغاريتمي التكميلي Complementary log-log link:
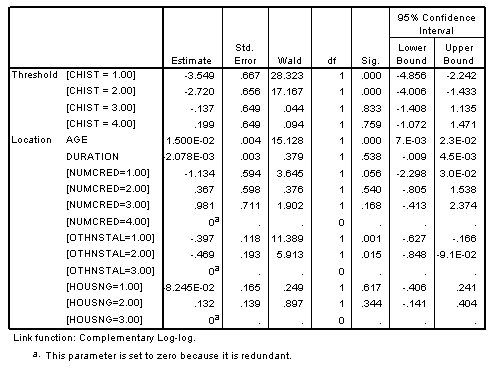
الدلالات
بعد اختيار النموذج باستخدام الارتباط اللوغاريتمي التكميلي Complementary log-log link، يمكنك إجراء بعض التفسيرات بناءً على تقديرات المعلمات parameter estimates.
- دلالة اختبار العمر بالسنوات أقل من 0.05، مما يشير إلى أن تأثيره الملحوظ لا يرجع إلى الصدفة. نظرًا لأن معاملها موجب، فكلما زاد العمر، تزداد أيضًا احتمالية التواجد في إحدى الفئات الأعلى لحالة الحساب.
- على النقيض من ذلك، فإن المدة بالأشهر تضيف القليل إلى النموذج.
- على الرغم من عدم وجود فئة واحدة من NUMCRED مهمة في حد ذاتها، إلا أن هناك فئتين مهمتين بشكل هامشي. عادة، يجدر الاحتفاظ بمثل هذا المتغير في النموذج، حيث تتراكم التأثيرات الصغيرة لكل فئة وتوفر معلومات مفيدة للنموذج. ومن المثير للاهتمام، أنه في حين أن أولئك الذين لديهم ائتمان واحد في البنك من المرجح أن يكونوا في فئات النتائج الأقل من أولئك الذين لديهم ائتمانات أكثر، فمن غير المرجح أن يكون أولئك الذين لديهم ائتمان أو ثلاثة ائتمانات في فئات النتائج الأقل من أولئك الذين لديهم أربعة ائتمانات.
- يبدو أيضًا أن OTHNSTAL مؤشر مهم على أسس تجريبية. أولئك الذين لديهم بعض الديون الأخرى على أقساط هم أكثر عرضة لأن يكونوا في فئات النتائج الأقل من أولئك الذين ليس لديهم.
- من ناحية أخرى، لا يبدو أن HOUSNG يساهم في النموذج بطريقة ذات مغزى ويمكن على الأرجح إسقاطه دون تفاقم النموذج بشكل كبير.
الخلاصة: استخدام نموذج الانحدار الترتيبي في التنبؤ
الاحتمالات المتوقعة
نظرًا لأن النموذج يحاول التنبؤ بالاحتمالات التراكمية بدلاً من عضوية الفئة، يلزم إجراء خطوتين للحصول على الفئات المتوقعة. أولاً، لكل حالة، يجب تقدير الاحتمالات لكل فئة. ثانيًا، يجب استخدام هذه الاحتمالات لتحديد فئة النتيجة الأكثر احتمالًا لكل حالة.
يتم تقدير الاحتمالات نفسها باستخدام قيم التوقع لحالة ما في معادلات النموذج وأخذ معكوس دالة الارتباط. والنتيجة هي الاحتمال التراكمي لكل مجموعة، المشروطة بنمط قيم المتنبئ للحالة. يمكن بعد ذلك اشتقاق احتمالات الفئات الفردية من خلال أخذ الفروق في الاحتمالات التراكمية للمجموعات بالترتيب. بمعنى آخر، فإن احتمال الفئة الأولى هو الاحتمال التراكمي الأول؛ احتمال الفئة الثانية هو الاحتمال التراكمي الثاني مطروحًا منه الأول؛ احتمال الفئة الثالثة هو الاحتمال التراكمي الثالث مطروحًا منه الثاني؛ وهكذا.
من الاحتمالات إلى قيم الفئة المتوقعة
لكل حالة، فئة النتائج المتوقعة هي ببساطة الفئة ذات الاحتمال الأعلى، بالنظر إلى نمط قيم التوقع لهذه الحالة. على سبيل المثال، لنفترض أن لديك متقدمًا يريد الحصول على قرض مدته 48 شهرًا (duration)، وعمره 22 عامًا (age)، ولديه ائتمان واحد مع البنك (numcred)، وليس عليه أي أقساط دين آخر (othnstal)، ويمتلك منزله (housing). بإدخال هذه القيم في معادلات التنبؤ، تنبأ مقدم الطلب هذا بقيم تبلغ -2.78 و -1.95 و 0.63 و 0.97. (تذكر أن هناك معادلة واحدة لكل فئة باستثناء الأخيرة.) وبأخذ معكوس دالة الارتباط اللوغاريتمي التكميلية log-log link function يعطي الاحتمالات التراكمية .06 و 0.13 و 0.85 و 0.93 (وبالطبع 1.0 للفئة الأخيرة). يعطي أخذ الفروق احتمالات الفئة الفردية التالية: الفئة 1: .06، الفئة 2: 0.13-0.06 = 0.07، الفئة 3: 0.85-0.13 = 0.72، الفئة 4: 0.93-0.85 = 0.08 ، والفئة 5: 1.0-0.93 = 0.07.
من الواضح أن الفئة 3 (مدفوعات الديون الجارية) debt payments current هي الفئة الأكثر ترجيحًا لهذه الحالة وفقًا للنموذج، مع احتمال متوقع قدره 0.72. وبالتالي، قد تتوقع أن يبقي مقدم الطلب مدفوعاته جارية ولن يصبح الحساب حرجًا.
الإجراءات ذات الصلة
يعتبر إجراء الانحدار الترتيبي أداة مفيدة لنمذجة متغير تابع ترتيبي.
- يستخدم إجراء الانحدار اللوجستي متعدد الحدود Multinomial Logistic Regression نموذجًا مشابهًا للتنبؤ بقيمة متغير تابع اسمي.
- إذا كان بإمكانك اعتبار المتغير التابع الخاص بك متغير مقياس scale variable، يمكنك بالتناوب استخدام إجراء الانحدار الخطي.
المصدر
- التحليل الإحصائي باستخدام برنامج SPSS، ترجمة وإعداد: د. م. مصطفى عبيد، مركز البحوث والدراسات متعدد التخصصات
- الموقع الرسمي لشركة IBM ® برنامج SPSS