استخدام تحليل التمييز لتصنيف عملاء الاتصالات
قام مزود الاتصالات بتقسيم قاعدة عملائه حسب أنماط استخدام الخدمة، وتصنيف العملاء إلى أربع مجموعات. إذا كان من الممكن استخدام البيانات الديموغرافية للتنبؤ بعضوية المجموعة عن طريق استخدام تحليل التمييز Discriminant Analysis، فيمكنك تخصيص العروض للعملاء المحتملين بشكل منفرد.
افترض أن المعلومات المتعلقة بالعملاء الحاليين موجودة في ملف telco.sav. راجع موضوع “ملفات الأمثلة” للحصول على مزيد من المعلومات. استخدم إجراء تحليل التمييز أو التحليل التمييزي Discriminant Analysis لتصنيف العملاء.
تشغيل تحليل التمييز
1. لتشغيل تحليل التمييز، اختر من القوائم: تحليل> تصنيف> تمييز …
Analyze > Classify > Discriminant…
يظهر مربع الحوار الرئيسي لإجراء تحليل التمييز Discriminant Analysis كما يلي:
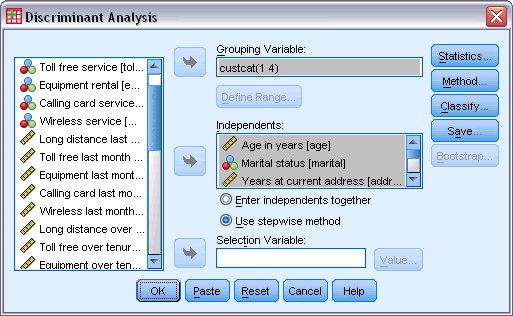
2. انقر فوق إعادة تعيين Reset لاستعادة الإعدادات الافتراضية.
3. إذا لم تعرض قائمة المتغيرات تسميات المتغيرات بحسب ترتيب الملفات، فانقر بزر الماوس الأيمن في أي مكان في قائمة المتغيرات variable list ومن قائمة السياق context، اختر عرض تسميات المتغيرات Display Variable Labels والفرز حسب ترتيب الملفات Sort by File Order.
4. حدد فئة العميل Customer category كمتغير التجميع grouping variable.
5. حدد الحقول من “العمر بالسنوات” Age in Years ولغاية “عدد الأفراد في الأسرة” Number of people in household كمتغيرات مستقلة independent variables.
6. حدد استخدام طريقة متدرجة Use stepwise method.
7. حدد فئة العميل Customer category وانقر فوق “تعريف النطاق” Define Range.
يظهر مربع حوار تحديد النطاق Define Range كما يلي:
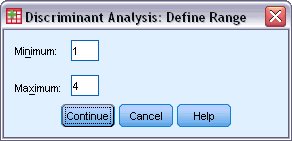
8. اكتب 1 كحد أدنى minimum.
9. اكتب 4 كحد أقصى maximum.
10. انقر فوق متابعة Continue.
11. انقر فوق تصنيف Classify في مربع حوار تحليل التمييز.
يظهر مربع حوار التصنيف Classification كما يلي:
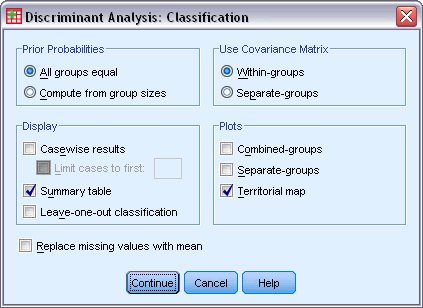
12. حدد جدول الملخص Summary table والخريطة الإقليمية Territorial map.
13. انقر فوق متابعة Continue.
14. انقر فوق “موافق” OK في مربع الحوار “تحليل التمييز”.
نتائج استخدام تحليل التمييز لتصنيف عملاء الاتصالات
تحليل التمييز المتدرج
الشكل التالي يبين المتغيرات غير الموجودة في التحليل، الخطوة 0:
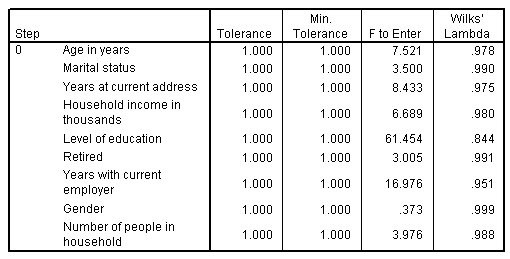
عندما يكون لديك الكثير من المتنبئين predictors، يمكن أن تكون الطريقة المتدرجة مفيدة عن طريق التحديد التلقائي للمتغيرات “الأفضل” لاستخدامها في النموذج. تبدأ الطريقة المتدرجة بنموذج لا يتضمن أيًا من المتنبئين. في كل خطوة، تتم إضافة المتنبئ الذي لديه أكبر قيمة من “F to Enter” التي تتجاوز معايير الدخول (افتراضيًا ، 3.84) إلى النموذج.
الشكل التالي يبين المتغيرات غير الموجودة في التحليل، الخطوة 3:
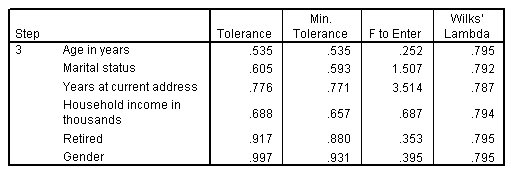
تحتوي جميع المتغيرات التي تم تركها من التحليل في الخطوة الأخيرة على قيم “F to Enter” أصغر من 3.84، لذلك لم تتم إضافة المزيد.
الشكل التالي يبين المتغيرات الموجودة في التحليل:
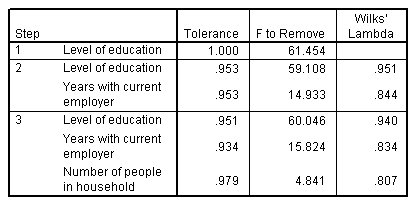
يعرض هذا الجدول إحصائيات المتغيرات الموجودة في التحليل في كل خطوة. التسامح Tolerance هو نسبة تباين المتغير الذي لا يتم تفسيره بواسطة المتغيرات المستقلة الأخرى في المعادلة. يساهم المتغير ذو التسامح المنخفض جدًا في القليل من المعلومات في النموذج ويمكن أن يتسبب في مشاكل حسابية.
تعتبر قيم “F to Remove” مفيدة لوصف ما يحدث إذا تمت إزالة متغير من النموذج الحالي (بالنظر إلى بقاء المتغيرات الأخرى). F to Remove لمتغير الإدخال هو نفسه F to Enter في الخطوة السابقة (كما هو موضح في جدول المتغيرات غير الموجودة في التحليل).
ملاحظة تنبيه بخصوص الطرق التدريجية
الطرق المتدرجة مريحة، لكن لها حدودها. اعلم أنه نظرًا لأن الأساليب المتدرجة تختار النماذج التي تستند فقط إلى الجدارة الإحصائية، فقد تختار تنبؤات ليس لها أهمية عملية. إذا كان لديك بعض الخبرة في البيانات ولديك توقعات حول أي من المتنبئين مهمين، فيجب عليك استخدام هذه المعرفة وتجنب الأساليب التدريجية. ومع ذلك، إذا كان لديك العديد من المتنبئين وليس لديك فكرة من أين تبدأ، فإن إجراء تحليل تدريجي وتعديل النموذج المحدد أفضل من عدم وجود نموذج على الإطلاق.
التحقق من ملاءمة نموذج تحليل التمييز
الشكل التالي يبين القيم الذاتية Eigenvalues:
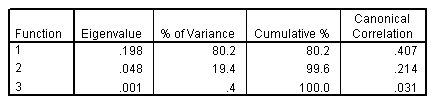
في الجدول أعلاه، يتم توضيح القيم الذاتية، ونسبة التباين، والنسبة المئوية التراكمية للتباين، والارتباط الكنسي لكل دالة تمييزية. يتم تفسير 80.2٪ من التباين من خلال الدالة الأولى، ويتم تفسير 99.6٪ من التباين من خلال الدالتين الأوليين
تقريبًا كل التباين الموضح بواسطة النموذج يرجع إلى أول دالتين تمييزيتين. يتم احتواء ثلاث دوال تلقائيًا، ولكن نظرًا لقيمتها الذاتية الضئيلة، يمكنك تجاهل الثالثة بأمان إلى حد ما.
الشكل التالي يبين Wilks’ lambda:
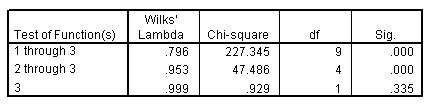
يوافق جدول Wilks ‘lambda على أن أول دالتن فقط مفيدتان. لكل مجموعة من الدوال، هذا يختبر الفرضية القائلة بأن متوسطات الدوال المدرجة متساوية عبر المجموعات. اختبار الدالة 3 له قيمة دلالة أكبر من 0.10، لذا فإن هذه الدالة تساهم قليلاً في النموذج.
مصفوفة البنية
الشكل التالي يبين مصفوفة البنية Structure matrix، وهي تبين جدول الارتباطات بين المتغيرات المستقلة والدوال التمييزية مع المتغيرات المستقلة في الصفوف والوظائف التمييزية في الأعمدة:
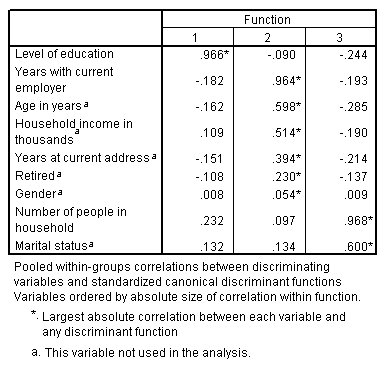
عندما يكون هناك أكثر من دالة تمييزية، فإن العلامة النجمية (*) تحدد أكبر ارتباط مطلق لكل متغير مع إحدى الدوال الأساسية. داخل كل دالة، يتم ترتيب هذه المتغيرات المحددة بالعلامة حسب حجم الارتباط.
- يرتبط مستوى التعليم Level of education ارتباطًا وثيقًا بالدالة الأولى، وهو المتغير الوحيد الأكثر ارتباطًا بهذه الوظيفة.
- السنوات مع صاحب العمل الحالي Years with current employer، والعمر بالسنوات Age in years، ودخل الأسرة بالآلاف Household income in thousands، والسنوات في العنوان الحالي Years at current address، والتقاعد Retired، والجنس Gender ترتبط ارتباطًا وثيقًا بالدالة الثانية، هذا على الرغم من أن الجنس Gender والتقاعد Retired مرتبطان بشكل أضعف من المتغيرات الأخرى. المتغيرات الأخرى تحدد هذه الدالة كدالة “استقرار” “stability” function.
- يرتبط عدد الأشخاص في الأسرة Number of people in household والحالة الاجتماعية Marital status ارتباطًا وثيقًا بالدالة التمييزية الثالثة، ولكن هذه دالة عديمة الفائدة، لذا فهذه تنبؤات عديمة الفائدة تقريبًا.
الخريطة الإقليمية
الشكل التالي يبين الخريطة الإقليمية Territorial map، ويظهر فيها دالة تمييز أساسية 2 على المحور الرأسي ودالة تمييز أساسية 1 على المحور الأفقي:

تساعدك الخريطة الإقليمية على دراسة العلاقات بين المجموعات الدوال التمييزية. إلى جانب نتائج مصفوفة الهيكل، فإنها تعطي تفسيرًا رسوميًا للعلاقة بين المتنبئين والمجموعات. الدالة الأولى، الموضحة على المحور الأفقي، تفصل المجموعة 4 (إجمالي عملاء الخدمة) Total service customers عن الآخرين. نظرًا لأن مستوى التعليم Level of education يرتبط ارتباطًا إيجابيًا وثيقًا بالدالة الأولى، فإن هذا يشير إلى أن عملاء الخدمة الإجمالية Total service customers هم، بشكل عام، الأكثر تعليماً. الدالة الثانية تفصل بين المجموعتين 1 و 3 (عملاء الخدمة الأساسية Basic service والخدمة الإضافية Plus service). يميل عملاء الخدمة الإضافية إلى العمل لفترة أطول وهم أقدم من عملاء الخدمة الأساسية. لا يتم فصل عملاء الخدمة الإلكترونية E-service جيدًا عن الآخرين، على الرغم من أن الخريطة تشير إلى أنهم يميلون إلى أن يكونوا متعلمين جيدًا ولديهم قدر معتدل من الخبرة في العمل.
بشكل عام، يشير القرب من النقط المركزية للمجموعة، المميزة بعلامات النجمة (*)، إلى الخطوط الإقليمية إلى أن الفصل بين جميع المجموعات ليس قويًا جدًا.
تم رسم أول دالتين مميزتين فقط، ولكن نظرًا لأنه تم العثور على أن الدالة الثالثة غير مهمة إلى حد ما، تقدم الخريطة الإقليمية رؤية شاملة للنموذج التمييزي.
نتائج التصنيف
الشكل لاتلاي يبين نتائج التصنيف، ويظهر فيه جدول التصنيف مع فئة العملاء الملاحظين في الصفوف والفئة المتوقعة في الأعمدة:
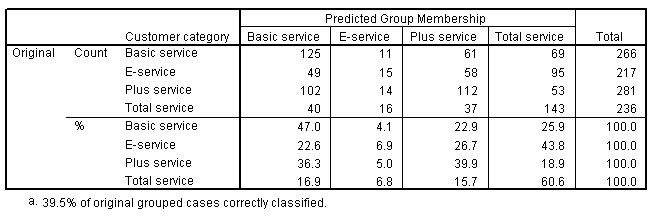
من lambda Wilks، أنت تعلم أن نموذجك يعمل بشكل أفضل من التخمين، ولكن عليك الرجوع إلى نتائج التصنيف لتحديد مدى التحسن. بالنظر إلى البيانات المرصودة، فإن النموذج “الفارغ” (أي النموذج الخالي من المتنبئين) سيصنف جميع العملاء في مجموعة مشروطة وهي الخدمات الإضافية Plus service. وبالتالي، سيكون النموذج الفارغ صحيحًا 281/1000 = 28.1٪ من الوقت. يحصل نموذجك على 11.4٪ أكثر من أو 39.5٪ من العملاء. على وجه الخصوص، يتفوق نموذجك في تحديد عملاء الخدمة الشاملة Total service. ومع ذلك، فإنه يقوم بعمل ضعيف للغاية في تصنيف عملاء الخدمة الإلكترونية E-service. قد تحتاج إلى البحث عن متنبئ آخر لفصل هؤلاء العملاء.
ملخص إجراء تحليل التمييز لتصنيف عملاء الاتصالات
لقد أنشأت نموذجًا تمييزيًا يصنف العملاء في واحدة من أربع مجموعات محددة مسبقًا “لاستخدام الخدمات” service usage، بناءً على المعلومات الديموغرافية من كل عميل. باستخدام مصفوفة الهيكل والخريطة الإقليمية، حددت المتغيرات الأكثر فائدة لتقسيم قاعدة عملائك. أخيرًا، أظهرت نتائج التصنيف أن أداء النموذج ضعيف في تصنيف عملاء الخدمة الإلكترونية E-service. مطلوب مزيد من البحث لتحديد متغير تنبؤ predictor variable آخر يصنف هؤلاء العملاء بشكل أفضل، ولكن اعتمادًا على ما تتطلع إلى توقعه، قد يكون النموذج مناسبًا تمامًا لاحتياجاتك. على سبيل المثال، إذا لم تكن مهتمًا بتحديد عملاء الخدمة الإلكترونية، فقد يكون النموذج دقيقًا بما يكفي بالنسبة لك. قد يكون هذا هو الحال عندما تكون الخدمة الإلكترونية رائدة الخسارة والتي تجلب القليل من الربح. إذا كان أعلى عائد على الاستثمار، على سبيل المثال، يأتي من عملاء الخدمة الإضافية Plus service أو عملاء الخدمة الإجمالية Total service، فقد يمنحك النموذج المعلومات التي تحتاجها.
للحصول على معلومات حول كيفية تقسيم الشركة لقاعدة عملائها في البداية، راجع استخدام متوسطات K لتصنيف العملاء Using K-Means to Classify Customers.
الإجراءات ذات الصلة
يعد إجراء تحليل التمييز Discriminant Analysis مفيدًا لنمذجة العلاقة بين متغير تابع فئوي categorical dependent variable وواحد أو أكثر من المتغيرات المستقلة من نوع المقياس scale independent variables.
إذا كان المتغير التابع هو من نوع المقياس، فاستخدم إجراء الانحدار الخطي Linear Regression.
أو بدلاً من ذلك، إذا كان المتغير التابع هو من نوع المقياس، فجرب إجراء النموذج الخطي العام أحدادي المتغير GLM Univariate.
إذا كانت المتنبئات متعددة الخطوط multicollinear وتريد تقليل عددها، فاستخدم إجراء تحليل العوامل Factor Analysis.
المصدر
- كتاب التحليل الإحصائي باستخدام برنامج SPSS، ترجمة وإعداد: د. م. مصطفى عبيد، مركز البحوث والدراسات متعدد التخصصات، إسطنبول، 2022.
- الموقع الرسمي لشركة IBM ® برنامج SPSS